Argo Workflows is widely used in scheduled tasks, machine learning, and ETL. If you are unfamiliar with Kubernetes, creating workloads based on YAML can be difficult. Hera is an Argo Workflows SDK for Python. Hera is an alternative to YAML and provides an easy method to orchestrate and test complex workflows in Python. In addition, Hera is seamlessly integrated with the Python ecosystem.
Feature overview
Argo Workflows uses YAML files to configure workflows for clarity and simplicity. The strict indent requirements and layered structure will make complex workflow configuration even harder if you are unfamiliar with YAML.
Hera is an Argo Workflows SDK for Python intended for workflow creation and submission based on Argo Workflows. Hera aims to simplify the procedures of creating and submitting workflows. Hera helps eliminate YAML syntax errors in complex workflow orchestration. Hera provides the following advantages:
Simplicity: Hera provides intuitive and easy-to-use code to greatly improve development efficiency.
Simple Python ecosystem integration: Each function is a template, which is seamlessly integrated with frameworks in the Python ecosystem. The Python ecosystem also provides various Python libraries and tools.
Observability: Hera supports Python testing frameworks to help improve code quality and maintainability.
Prerequisites
The Argo components and console are installed and the credentials and the IP address of Argo Server are obtained. For more information, see Enable batch task orchestration.
Hera is installed.
pip install hera-workflows
Scenario 1: Simple DAG Diamond
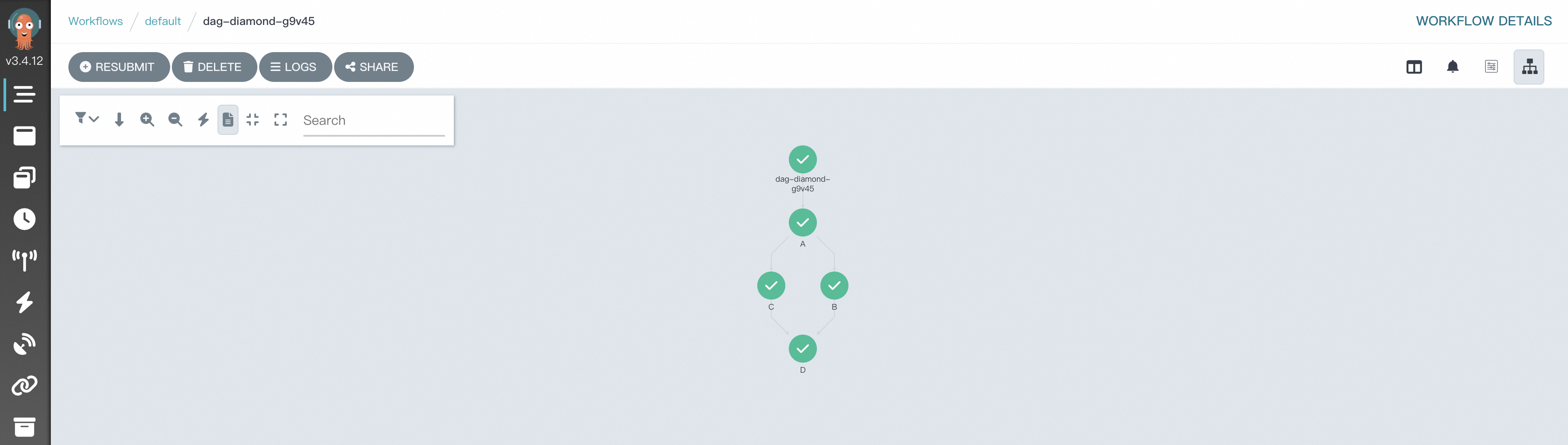
Argo Workflows uses directed acyclic graphs (DAGs) to define complex dependencies for tasks in a workflow. The Diamond structure is commonly adopted by workflows. In a Diamond workflow, the execution results of multiple parallel tasks are aggregated into the input of a subsequent task. The Diamond structure can efficiently aggregate data flows and execution results. The following sample code shows how to use Hera to orchestrate a Diamond workflow where Task A and Task B run in parallel and the execution results of Task A and Task B are aggregated into the input of Task C.
Create a file named simpleDAG.py and copy the following content to the file:
# Import the required packages. from hera.workflows import DAG, Workflow, script from hera.shared import global_config import urllib3 urllib3.disable_warnings() # Specify the endpoint and token of the workflow cluster. global_config.host = "https://${IP}:2746" global_config.token = "abcdefgxxxxxx" # Enter the token you obtained. global_config.verify_ssl = "" # The script decorator is the key to enabling Python-like function orchestration by using Hera. # You can call the function below a Hera context manager such as a Workflow or Steps context. # The function still runs as normal outside Hera contexts, which means that you can write unit tests on the given function. # The following code provides a sample input. @script() def echo(message: str): print(message) # Orchestrate a workflow. The Workflow is the main resource in Argo and a key class of Hera. The Workflow is responsible for storing templates, setting entry points, and running templates. with Workflow( generate_name="dag-diamond-", entrypoint="diamond", namespace="argo", ) as w: with DAG(name="diamond"): A = echo(name="A", arguments={"message": "A"}) # Create a template. B = echo(name="B", arguments={"message": "B"}) C = echo(name="C", arguments={"message": "C"}) D = echo(name="D", arguments={"message": "D"}) A >> [B, C] >> D # Define dependencies. In this example, Task A is the dependency of Task B and Task C. Task B and Task C are the dependencies of Task D. # Create the workflow. w.create()Run the following command to submit the workflow:
python simpleDAG.pyAfter the workflow starts running, you can go to the Workflow Console (Argo) to view the DAG process and the result.
Scenario 2: MapReduce
In Argo Workflows, the key to processing data in the MapReduce style is to use DAG templates to organize and coordinate multiple tasks in order to simulate the Map and Reduce phases. The following sample code shows how to use Hera to orchestrate a sample MapReduce workflow that is used to count words in text files. Each step is defined in a Python function to integrate with the Python ecosystem.
To configure artifacts, see Configure artifacts.
Create a file named map-reduce.py and copy the following content to the file:
Run the following command to submit the workflow:
python map-reduce.pyAfter the workflow starts running, you can go to the Workflow Console (Argo) to view the DAG process and the result.

References
The Hera documentation:
For more information about Hera, see Hera overview.
For more information about how to use Hera to train large language models (LLMs), see Train LLM with Hera.
Sample YAML deployment configurations:
For more information about how to use YAML files to deploy simple-diamond, see dag-diamond.yaml.
For more information about how to use YAML files to deploy map-reduce, see map-reduce.yaml.
Contact us
If you have suggestions or questions about this product, join the DingTalk group 35688562 to contact us.