You can use the configuration file to specify multiple tasks and their dependencies and then run the following command to submit the file:
bcs sub --file job.cfg # The file name is editable.Support for a single task
The job.cfg file is as follows:
[taskname]
cmd=python test.py
job_name=demo
cluster=img=img-ubuntu:type=ecs.sn1.medium
description=test job
nodes=1
pack=./src/
read_mount=oss://bucket/input/:/home/input/
write_mount=oss://bucket/output/:/home/output/This configuration file contains a [taskname] section. The section name taskname is submitted as the name of the task.
Except for cmd and job_name, other options use the full names shown by the bcs sub -h command, which is equivalent to the result of the
--${option}command.
Support for multiple tasks
You can also configure multiple tasks and their dependencies in the configuration file.
The job.cfg file is as follows:
[DEFAULT]
job_name=log-count
description=demo
force=True
deps=split->count;count->merge
# The following are public configurations of the task:
env=public_key:value,key2:value2
read_mount=oss://bucket/input/:/home/input/
write_mount=oss://bucket/output/:/home/output/
pack=./src/
[split]
cmd=python split.py
cluster=img=img-ubuntu:type=ecs.sn1.medium
nodes=1
[count]
cmd=python count.py
cluster=img=img-ubuntu:type=ecs.sn1.medium
nodes=3
[merge]
cmd=python merge.py
cluster=img=img-ubuntu:type=ecs.sn1.medium
nodes=1The [DEFAULT] section specifies the job configurations, and other sections specify the configurations of tasks. The name of a section is also the task name.
Priority of options: An
--${option}in a command line has the highest priority, followed by the options specified in the task sections, and then the options in the DEFAULT section.The env, read_mount, write_mount, and mount options can be merged. Other options are directly overwritten by higher-priority options.
deps=split->count;count->mergespecifies the dependencies between the tasks. A split task is followed by a count task, which is followed by a merge task.The img and type parameters in cluster options vary with regions. You must configure these parameters based on the region that you have selected.
1. About deps
If the DAG is as follows:
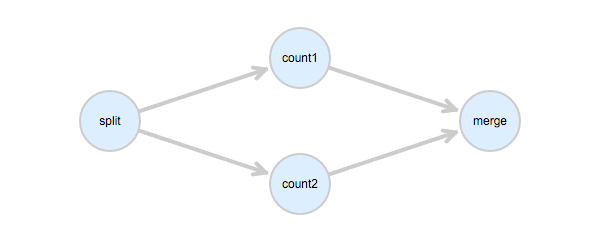
Configure deps as follows:
deps=split->count1,count2;count1->merge;count2->mergeEach dependency is a one-to-multiple match: task1 matches task2 and task3.
Tasks are separated by commas, while dependencies by semicolons.
2. About pack
./src/
|-- split.py
|-- ...If a directory is specified in pack, for example, pack=./src/, all files in src are compressed into worker.tar.gz. The file name with the ./src/ directory must be specified in cmd, for example, cmd=python split.py.
If a file is specified in pack, for example, pack=./src/split.py, only the file is compressed into worker.tar.gz. Only the file name is specified in cmd, for example, cmd=python split.py.
The pack option can be configured in the [DEFAULT] section, in each task section, or in the command lines.
3. About mount
read_mount specifies one or more read-only OSS directories to be mounted to the file system of the VM which the application runs on. In a Linux operating system, an OSS directory can be mounted as a directory; in a Windows operating system, a directory must be mounted as a drive, “E:” for example.
To mount multiple directories, separate them with commas, for example,read_mount=oss://bucket/input/:/home/input/,oss://bucket/input2/:/home/input2/. The rule also applies to write_mount and mount.
write_mount specifies one and only writable OSS directory to be mounted to the directory of the VM which the application runs on. If the directory does not exist, you can create one. All files written into this directory are uploaded to the mounted OSS directory.
Mount specifies the same directory for read_mount and write_mount. This parameter is not recommended.
4. About cluster
Can define cluster in two formats:
AutoCluster:
cluster=img=<img-id>:type=<instance-type>An AutoCluster task automatically creates a cluster with the specified configuration while the specified task is running. After the task is complete, the cluster is released automatically.
Cluster:
cluster=<cluster-id>Run “bcs c” to view your clusters. If no cluster exists, create one.
For example:
bcs cc <cluster-name> -i <img-id> -t <instance-type> -n 3“-n 3” indicates that three VMs are expected to run the application.
“-i img-id” specifies the image ID.
“-t instance-type” specifies an instance type. You can run
bcs itto view the available instance types.For other options, you can run
bcs cc -hto view the descriptions.
Clusters significantly shorten the startup time of a job. However, a cluster keeps running and being billed. We recommend that you must maintain a balance between the use of clusters and the costs.
5. About Docker
Syntax:
docker=myubuntu@oss://bucket/dockers/A Docker works only if an ImageId that supports Docker is specified. If no cluster is specified, the default imageId supports Docker. Alternatively, you can explicitly specify a cluster or clusterId, of which the ImageId supports Docker.
The full name of myubuntu is localhost:5000/myubuntu. A Docker image must be prefixed with localhost:5000/, which is omitted here. The OSS directory is the directory of a private Docker image warehouse on the OSS instance. For more information, see How to use a Docker.
6. About nodes
Nodes indicate the number of VMs used for running the task.
7. About force
If the force is True, the job keeps running in the case that a VM fails to run the application. If the force is False, the job fails when a VM fails to run the application. Default value: False