This topic describes how to archive data by submitting a ticket.
Background
When the amount of data in an online database increases, the query performance and business operations may be affected. OceanBase Developer Center (ODC) allows you to periodically archive table data from one database to another to address this issue.
The example in this topic describes how to create a data archiving task in ODC to archive the employee table in the odc_test database to the test2 database in the same project.
All data in this example is for reference only. You can replace the data as needed.
Considerations
Pay attention to the following rules:
The table to be archived must have a primary key. If the table belongs to an OceanBase MySQL-compatible or a native MySQL data source, it can be archived if it has a unique index.
The database user for archiving data must have the read/write permissions and the permission to access internal views. For information about permission configuration, see View user privileges, Overview, and Modify user privileges.
The columns in the source table must be compatible with those at the target. The data archiving service does not handle compatibility issues.
Schema synchronization is not supported for subpartitions of homogeneous databases. Schema synchronization and automatic table creation are not supported for heterogeneous databases.
The following archiving links are supported:
Links between OceanBase MySQL-compatible data sources
Links between OceanBase Oracle-compatible data sources
Links from OceanBase MySQL-compatible and OceanBase Oracle-compatible data sources to object storage services, such as Alibaba Cloud Object Storage Service (OSS), Tencent Cloud Object Storage (COS), Huawei Cloud Object Storage Service (OBS), and Amazon Simple Storage Service (S3).
Data archiving is not supported in the following cases:
The source table in the OceanBase MySQL-compatible data source contains columns of the XMLType data type.
The source table in the OceanBase Oracle-compatible data source contains columns of the JSON or XMLType data type.
The archiving condition contains a LIMIT clause.
The source table contains a foreign key.
Automatic table creation is supported for the following archiving links:
Links between OceanBase Oracle-compatible data sources
Links between OceanBase MySQL-compatible data sources
Schema synchronization is supported for the following archiving links:
Links between OceanBase MySQL-compatible data sources
Create a data archiving task
In the SQL development window, create a table named employee by using an SQL statement.
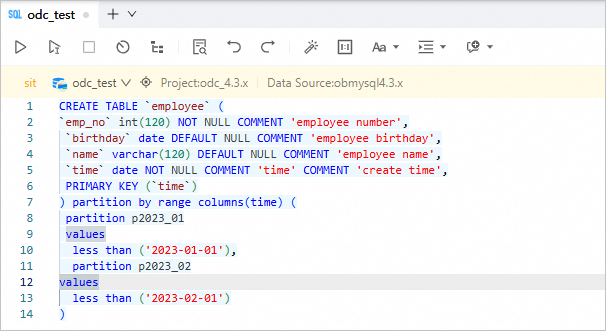
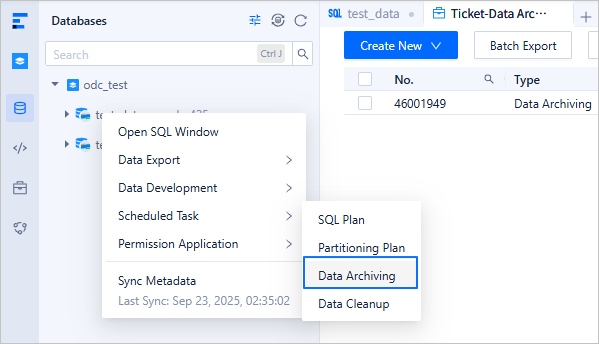
CREATE TABLE `employee` ( `emp_no` int(120) NOT NULL COMMENT 'employee number', `birthday` date DEFAULT NULL COMMENT 'employee birthday', `name` varchar(120) DEFAULT NULL COMMENT 'employee name', `time` date NOT NULL COMMENT 'time' COMMENT 'create time', PRIMARY KEY (`time`) ) partition by range columns(time) ( partition p2023_01 values less than ('2023-01-01'), partition p2023_02 values less than ('2023-02-01') )In the database list, right-click the name of the target database and choose Scheduled Task > Data Archiving to go to the page for creating a data archiving task. You can also choose Tickets > Data Archiving in the left-side navigation pane and then click Create New.
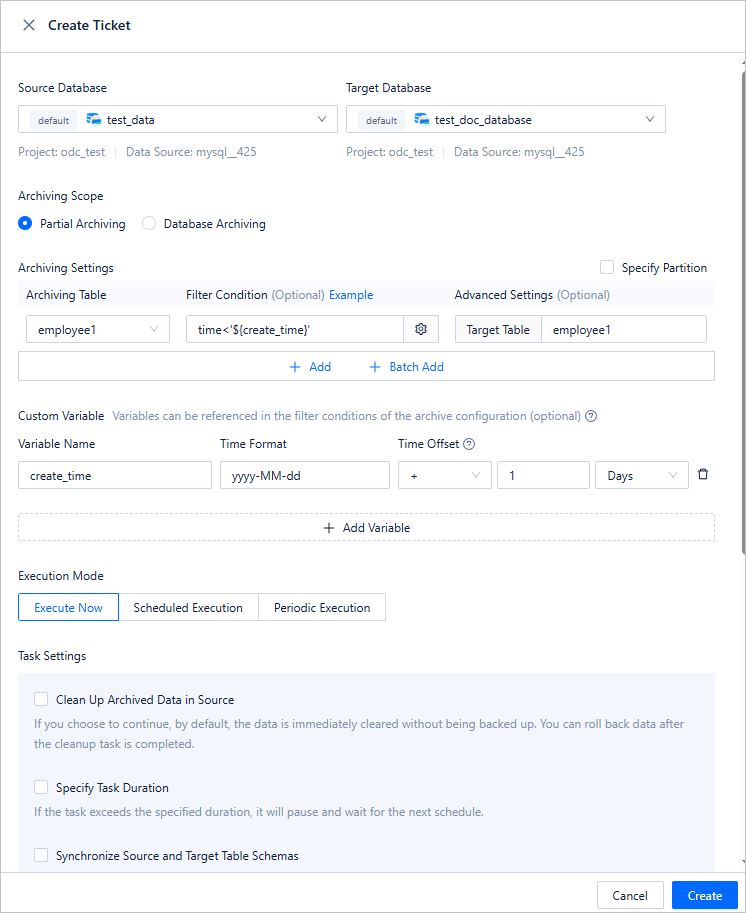
In the Create Ticket panel, configure the following parameters.
Parameter
Description
Source Database
The database to which the table belongs.
NoteIn ODC V4.2.2 and later, you can archive data from a MySQL database to OceanBase Database.
Target Database
The database to which the table is to be archived.
NoteIn ODC V4.2.2 and later, you can archive data from OceanBase Database to a MySQL database.
Archiving Scope
Partial Archiving: specifies to archive only tables that meet filtering conditions in the source database.
You can configure filtering conditions by using constants or referencing variables defined in Custom Variable. For example, in
time<'${create_time}',create_timeis the name of a variable configured in Custom Variable andtimeis a column in the table to be archived.NoteYou can set filtering conditions for associated tables.
You can select Specify Partition and specify the partitions to be archived.
Click + Add to add a table to be archived and archive the table to the target database.
Click + Batch Add to add multiple tables to be archived and archive the tables to the target database.
Database Archiving: specifies to archive all tables in the source database.
Custom Variable
Optional. You can define variables and set time offsets to filter rows to be archived.
Execution Mode
The execution mode of the task. Valid values: Execute Now, Scheduled Execution, and Periodic Execution.
Task Settings
Clean Up Archived Data in Source: If you select this option, data in the source is cleaned up based on the settings. By default, the data is immediately cleaned up and not backed up. You can roll back the cleanup task.
Specify Task Duration: You can select this option and specify a duration for the task. If the task is not completed within the specified duration, it will be suspended and wait for the next scheduling.
Synchronize Source and Target Table Schemas: You can select this option to compare the table schemas of the source and target before the archiving task is scheduled. If they are inconsistent, the source table is skipped.
Insert Policy: You can choose whether to ignore or update duplicate data during data archiving.
Search strategy: Full-table scan and conditional matching are supported.
Set Limit: You can specify Row Limit and Data Size Limit.
Description
Optional. Additional information about the task, which cannot exceed 200 characters in length.
Click Create, preview the SQL statement for archiving, and click OK.
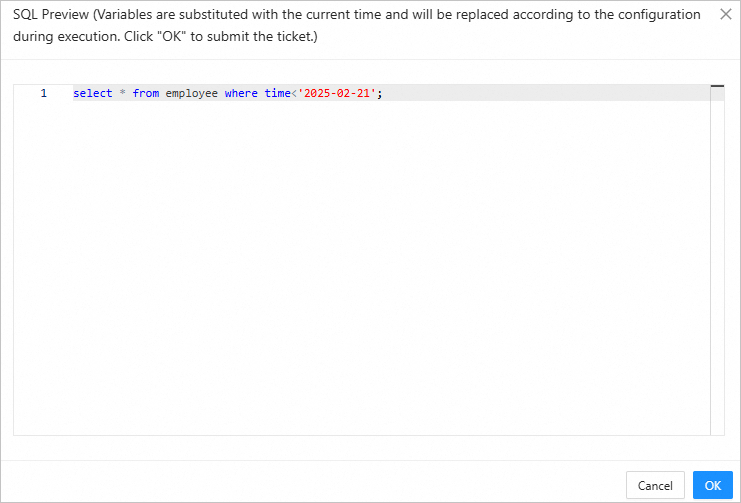
After the task is generated, choose Tickets > Data Archiving to view the task.

View a data archiving task
Task information
In the data archiving task list on the Tickets tab, click View in the Actions column of a task.
In the ticket details panel, click the Basic Information tab and view information such as the task type, source database, target database, variable configurations, archiving scope, and execution mode.
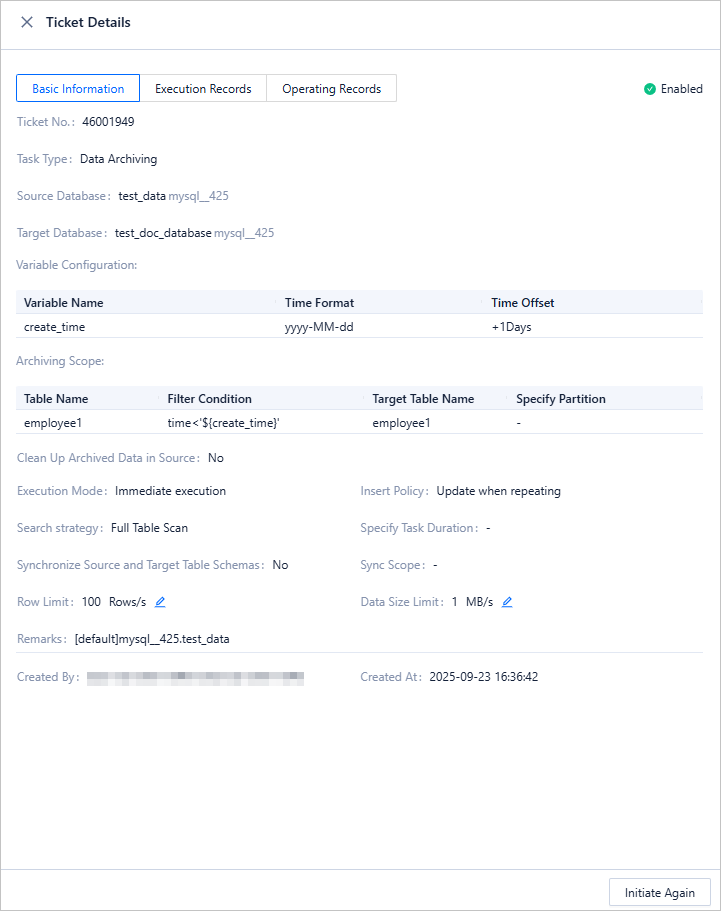
Click Initiate Again in the lower-right corner. The data archiving information is copied to the Create Ticket panel, allowing you to quickly create a data archiving task.
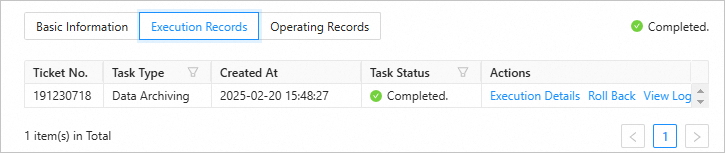
Execution records
In the ticket details panel, click the Execution Records tab and view the task status and execution details.
Operating records
In the ticket details panel, click the Operating Records tab and view the approval status and change history of the task.

Import data archiving tasks
You can migrate instances as well as their data archiving tasks from ApsaraDB for OceanBase to OceanBase Cloud.
Step 1: Export data archiving tasks from ApsaraDB for OceanBase
Log on to the ApsaraDB for OceanBase console. Click Instances in the left-side navigation pane.
Click Cut to Cloud Market in the Actions column of the target instance.

After that, click Processing data research and development tasks in the Actions column of the instance.

On the Processing data research and development tasks page, click View and Export All to export scheduled tasks to your local computer.

Step 2: Import data archiving tasks to OceanBase Cloud
Log on the OceanBase Cloud console and choose Data Services > Data Lifecycle. On the Data Lifecycle page, click ... and select Import Job.

Upload the data archiving configuration file downloaded to your local computer earlier to the import job.