In a distributed system, any service can fail at any time -- an upstream might stop responding, a connection might reset, or a dependency might buckle under load. Without safeguards, one failing component can cascade and bring down the entire system.
Service Mesh (ASM) provides four fault tolerance mechanisms at the sidecar proxy layer: timeouts, retries, the bulkhead pattern, and circuit breaking. Because these policies are enforced by the proxy, your applications gain resilience without code changes.
Timeouts
How it works
A timeout sets a maximum wait time for a response. If an upstream service does not respond within this period, the sidecar proxy returns an error to the caller instead of waiting indefinitely.
A few important nuances:
A timeout error does not mean the upstream operation failed. The upstream may still complete processing after the caller gives up.
Timeouts free up caller resources that would otherwise be blocked waiting.
After a timeout, the application can take a fallback action such as returning cached data or a default response.
Configure a timeout
Set a timeout on a route in a VirtualService. This example sets a 5-second timeout for all requests routed to the httpbin service:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
timeout: 5s| Field | Description |
|---|---|
timeout | Maximum time the sidecar proxy waits for a response. If the upstream does not respond within this period, the proxy returns a timeout error to the caller. |
The timeout applies to every request that matches this route.
Retries
How it works
When a request fails due to a transient issue -- a connection timeout, a reset, or a brief service outage -- an automatic retry can recover without manual intervention.
Retries increase load on the target service. Misconfigured retries can amplify failures instead of recovering from them.
Only retry idempotent operations -- requests that produce the same result no matter how many times they run. Retrying non-idempotent operations (such as creating a charge or sending a notification) can cause duplicate side effects.
Set
perTryTimeoutto cap the duration of each attempt.When both a retry policy and a route-level timeout are configured, the route timeout governs total time across all attempts. If total retry time exceeds the route timeout, the proxy stops retrying and returns a timeout error.
Configure a retry policy
Define a retry policy in a VirtualService. This example retries requests to httpbin up to 3 times on connection failure or reset, with a 5-second timeout per attempt:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- 'httpbin'
http:
- route:
- destination:
host: httpbin
retries:
attempts: 3
perTryTimeout: 5s
retryOn: connect-failure,reset| Field | Description |
|---|---|
attempts | Maximum retry attempts. If a route timeout is also set, the actual number of retries may be lower -- the proxy stops retrying when total elapsed time exceeds the route timeout. |
perTryTimeout | Timeout for each retry attempt. Supported units: milliseconds, seconds, minutes, hours. |
retryOn | Comma-separated list of conditions that trigger a retry. See the tables below. |
HTTP retry conditions
| Condition | Triggers a retry when... |
|---|---|
connect-failure | The connection to the upstream fails (for example, connection timeout). |
refused-stream | The upstream returns a REFUSED_STREAM frame to reset the stream. |
reset | A disconnection, reset, or read timeout occurs before the upstream responds. |
5xx | The upstream returns a 5xx status code (such as 500 or 503) or does not respond. This condition includes connect-failure and refused-stream. |
gateway-error | The upstream returns a 502, 503, or 504 status code. |
envoy-ratelimited | The response contains the x-envoy-ratelimited header. |
retriable-4xx | The upstream returns a 409 status code. |
retriable-status-codes | The upstream returns a status code listed in the retry policy. For example, retryOn: 403,404,retriable-status-codes. |
retriable-headers | The response contains a header listed in the x-envoy-retriable-header-names request header. For example, adding x-envoy-retriable-header-names: X-Upstream-Retry,X-Try-Again to request headers triggers retries when either of those headers appears in the response. |
gRPC retry conditions
gRPC uses HTTP/2 as its transport protocol. Set gRPC retry conditions in the retryOn field alongside HTTP conditions.
| Condition | Triggers a retry when... |
|---|---|
cancelled | The gRPC status code is CANCELLED (1). |
unavailable | The gRPC status code is UNAVAILABLE (14). |
deadline-exceeded | The gRPC status code is DEADLINE_EXCEEDED (4). |
internal | The gRPC status code is INTERNAL (13). |
resource-exhausted | The gRPC status code is RESOURCE_EXHAUSTED (8). |
Default HTTP retry policy
ASM applies a default retry policy to all HTTP requests, even when no VirtualService retry policy is defined:
| Setting | Default value |
|---|---|
| Retries | 2 |
| Timeout per retry | None (no per-retry timeout) |
| Retry conditions | connect-failure, refused-stream, unavailable, cancelled, retriable-status-codes |
The default retry policy requires ASM instances version 1.15.3.120 or later. To update your ASM instance, see Update an ASM instance.
Customize the default retry policy
Override the default policy in the ASM console:
Log on to the ASM console. In the left-side navigation pane, choose Service Mesh > Mesh Management.
On the Mesh Management page, click the name of the ASM instance. In the left-side navigation pane, choose ASM Instance > Base Information.
In the Config Info section of the Base Information page, click Edit next to Default HTTP retry policy.
In the Default HTTP retry policy dialog box, set the parameters and click OK.
| Parameter | Description |
|---|---|
| Retries | Maximum number of retries (attempts). Set to 0 to disable default retries entirely. |
| Timeout | Timeout for each retry attempt (perTryTimeout). |
| Retry On | Conditions that trigger a retry (retryOn). |
Bulkhead pattern
How it works
The bulkhead pattern caps the number of concurrent connections and requests a client can make to a service. When the limit is reached, new requests are rejected immediately with a 503 error instead of queuing indefinitely. This isolates failures: a slow or unresponsive service cannot exhaust the connection pool and starve other services.

Connection pool settings work at two levels:
TCP level (applies to TCP, HTTP, and gRPC): maximum concurrent connections and connection timeout.
HTTP level (applies to HTTP/1.1, HTTP/2, and gRPC): maximum pending requests and maximum requests per connection.
Configure the bulkhead pattern
Define connection pool limits in a DestinationRule. This example caps connections to httpbin at 1 concurrent connection, 1 pending request, and 1 request per connection, with a 10-second connection timeout:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
connectTimeout: 10s
maxConnections: 1| Field | Description | Tuning guidance |
|---|---|---|
maxConnections | Maximum number of TCP connections to the upstream host. | Increase for high-throughput services. Decrease to limit the blast radius of a slow upstream. |
connectTimeout | Maximum time to establish a TCP connection. Returns a 503 error on timeout. | Set based on expected network latency. Too low causes false failures; too high delays error detection. |
http1MaxPendingRequests | Maximum number of requests queued while waiting for a connection. | Increase if legitimate traffic bursts are common. Decrease to shed load early under pressure. |
maxRequestsPerConnection | Maximum number of requests per connection. After this limit, the connection is closed and a new one is established. | Set to 1 to prevent connection reuse (useful for debugging). Increase for steady-state workloads to reduce connection overhead. |
Circuit breaking
How it works
Circuit breaking detects unhealthy upstream hosts and temporarily removes (ejects) them from the load balancing pool. The sidecar proxy tracks each upstream host's error rate independently. When a host accumulates consecutive errors beyond a threshold, all traffic is redirected to the remaining healthy hosts. After the ejection period expires, the host is added back to the pool.
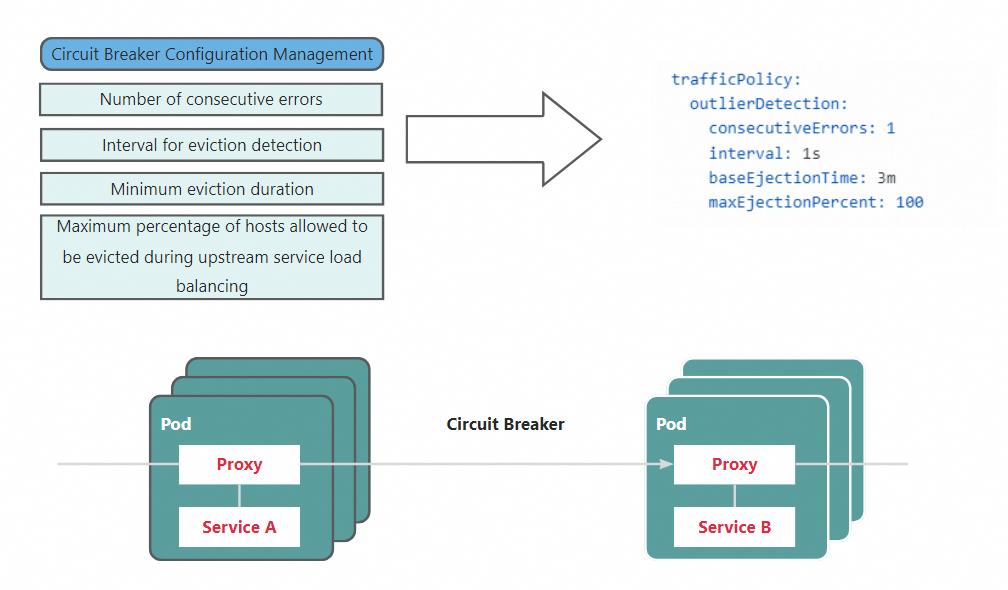
This host-level circuit breaking mechanism (outlier detection) differs from both the connection-level limits configured in the bulkhead pattern and the circuit breaking mechanism defined by using ASMCircuitBreaker fields. Together, outlier detection and the bulkhead pattern form a comprehensive resilience strategy:
Bulkhead pattern: Limits total connections and requests to a service (connection pool).
Circuit breaking: Removes individual unhealthy hosts from the pool (outlier detection).
Configure circuit breaking
Define outlier detection rules in a DestinationRule. This example ejects a host from the httpbin load balancing pool for 5 minutes if it fails 3 consecutive requests within a 5-second detection window:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
outlierDetection:
consecutiveErrors: 3
interval: 5s
baseEjectionTime: 5m
maxEjectionPercent: 100| Field | Description | Tuning guidance |
|---|---|---|
consecutiveErrors | Number of consecutive errors before a host is ejected. | Lower values eject hosts faster, improving success rates but potentially reducing available capacity. Higher values tolerate brief error spikes without ejecting hosts. |
interval | Time window for error detection. | Shorter intervals detect failures faster. Longer intervals smooth out transient errors. |
baseEjectionTime | Minimum duration a host stays ejected. The actual ejection time increases with repeat ejections. | Shorter durations let hosts recover and rejoin quickly. Longer durations reduce traffic to persistently unhealthy hosts. |
maxEjectionPercent | Maximum percentage of hosts in the pool that can be ejected simultaneously. | Set below 100 to guarantee that some hosts always remain available, even if unhealthy. Set to 100 to allow full ejection when you have alternative fallback paths. |
Monitor circuit breaking metrics
When a host is ejected, the sidecar proxy generates metrics that track ejection activity. Use these metrics to detect and diagnose circuit breaking events.
| Metric | Type | Description |
|---|---|---|
envoy_cluster_outlier_detection_ejections_active | Gauge | Number of hosts currently ejected from the load balancing pool. |
envoy_cluster_outlier_detection_ejections_enforced_total | Counter | Total number of host ejection events. |
envoy_cluster_outlier_detection_ejections_overflow | Counter | Number of ejection attempts that were skipped because maxEjectionPercent was reached. |
ejections_detected_consecutive_5xx | Counter | Number of consecutive 5xx errors detected on a host. |
To enable these metrics on the sidecar proxy:
Configure
proxyStatsMatcherin the sidecar proxy settings. Select Regular Expression Match and set the value to.*outlier_detection.*. For details, see the proxyStatsMatcher section in Configure sidecar proxies.Redeploy the workloads that use the sidecar proxy. For details, see the "Redeploy workloads" section in Configure sidecar proxies.
Set up alerts for circuit breaking
Once metrics are flowing, configure alerts in Managed Service for Prometheus to get notified when circuit breaking triggers.
In Managed Service for Prometheus, connect the ACK cluster on the data plane to the Alibaba Cloud ASM component, or upgrade it to the latest version. This ensures circuit breaking metrics are collected. For details, see Manage components.
Skip this step if you already collect ASM metrics with a self-managed Prometheus instance. See Monitor ASM instances by using a self-managed Prometheus instance.
Create an alert rule using a custom PromQL statement. For details, see Create alert rules for Prometheus instances. Example parameter values for a circuit breaking alert:
Parameter Example value Description Custom PromQL statement (sum (envoy_cluster_outlier_detection_ejections_active) by (cluster_name, namespace)) > 0Checks whether any hosts are currently ejected, grouped by namespace and service name. Alert message Host-level circuit breaking is triggered. Some workloads encounter errors repeatedly and the hosts are ejected from the load balancing pool. Namespace: {{$labels.namespace}}, Service: {{$labels.cluster_name}}. Ejected hosts: {{ $value }}Includes the namespace, service name, and number of ejected hosts.
What's next
Configure sidecar proxies -- Customize sidecar proxy behavior, including proxy stats matching for circuit breaking metrics.
Update an ASM instance -- Upgrade your ASM instance to access the latest fault tolerance features, including the default HTTP retry policy (requires version 1.15.3.120 or later).