GPU sharing overview
This topic introduces the GPU sharing solution provided by Alibaba Cloud, describes the benefits of GPU Sharing Professional Edition, and compares the features and use scenarios of GPU Sharing Basic Edition and GPU Sharing Professional Edition. This helps you better understand and use GPU sharing.
Background information
GPU sharing allows you to run multiple containers on the same GPU device. After Alibaba Cloud Container Service for Kubernetes (ACK) makes GPU sharing open-source, you can implement a GPU sharing framework on container clusters in both Alibaba Cloud and on-premises data centers. This enables multiple containers to share the same GPU device, thereby reducing usage costs.
However, while achieving cost efficiency, it is also essential to ensure the stable operation of containers on the GPU. By isolating the GPU resources that are allocated to each containe, the resource usage of each containers on the same GPU can be limited, preventing mutual interference caused by resource overuse. To solve this issue, many solutions are provided in the computing industry, such as NVIDIA vGPU, Multi-Process Service (MPS), and vCUDA, to achieve more refined GPU usage management.
To meet these requirements, ACK introduced the GPU sharing solution. This solution not only allows a single GPU to be shared by multiple tasks, but also achieves memory isolation and GPU computing power partitioning for different applications on the same GPU.
Features and benefits
The GPU sharing solution uses the server kernel driver that is developed by Alibaba Cloud to provide more efficient use of the underlying drivers of NVIDIA GPUs. GPU sharing provides the following features:
High compatibility: GPU sharing is compatible with standard open source solutions, such as Kubernetes and NVIDIA Docker.
Ease of use: GPU sharing provides excellent user experience. To replace a Compute Unified Device Architecture (CUDA) library of an AI application, you do not need to recompile the application or create a new container image.
Stability: GPU sharing provides stable underlying operations on NVIDIA GPUs. API operations on CUDA libraries and some private API operations on CUDA Deep Neural Network (cuDNN) are difficult to call.
Resource isolation: GPU sharing ensures that the allocated GPU memory and computing power do not affect each other.
GPU sharing provides a cost-effective, reliable, and user-friendly solution that allows you to enable GPU scheduling and memory isolation.
Benefit | Description |
Supports GPU sharing, scheduling, and memory isolation. |
|
Supports flexible GPU sharing and memory isolation policies. |
|
Supports comprehensive monitoring of GPU resources. | Supports monitoring of both exclusive GPUs and shared GPUs. |
Free of charge | You must activate the cloud-native AI suite before using GPU sharing. Starting from 00:00:00 (UTC+8) on June 6, 2024, the Cloud Native AI Suite are fully open for free use. |
Usage notes
GPU sharing supports only ACK Pro clusters. For more information about how to install and use GPU sharing, see the following topics:
You can also use the following advanced features provided by GPU sharing:
Terms
Share mode and exclusive mode
The share mode allows multiple pods to share one GPU, as shown in the following figure. 
The exclusive mode allows a pod to occupy one or more GPUs exclusively, as shown in the following figure. 
GPU memory isolation
GPU sharing can only ensure that multiple pods run on one GPU but cannot prevent resource contention among the pods when GPU memory isolation is disabled. The following section shows an example.
Pod 1 requests 5 GiB of GPU memory and Pod 2 requests 10 GiB of GPU memory. When GPU memory isolation is disabled, Pod 1 can use up to 10 GiB of GPU memory, including the 5 GiB of GPU memory requested by Pod 2. Consequently, Pod 2 fails to launch due to insufficient GPU memory. After GPU memory isolation is enabled, when Pod 1 attempts to use GPU memory greater than the requested value, the GPU memory isolation module forces Pod 1 to fail. 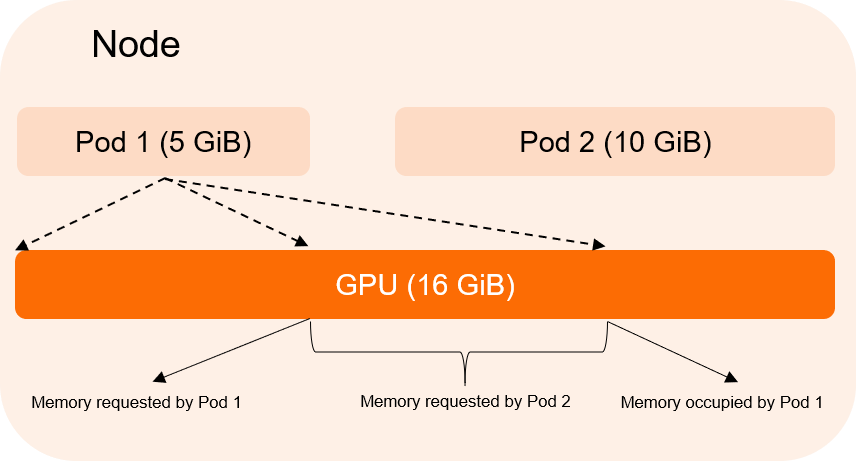
GPU scheduling policies: binpack and spread
If a node with the GPU sharing feature enabled has multiple GPUs, you can choose one of the following GPU selection policies:
Binpack: By default, the binpack policy is used. The scheduler allocates all resources of a GPU to pods before you switch to another GPU. This helps prevent GPU fragments.
Spread: The scheduler attempts to spread pods to different GPUs on the node in case business interruptions occur when a GPU is faulty.
In this example, a node has two GPUs. Each GPU provides 15 GiB of memory. Pod1 requests 2 GiB of memory and Pod2 requests 3 GiB of memory.

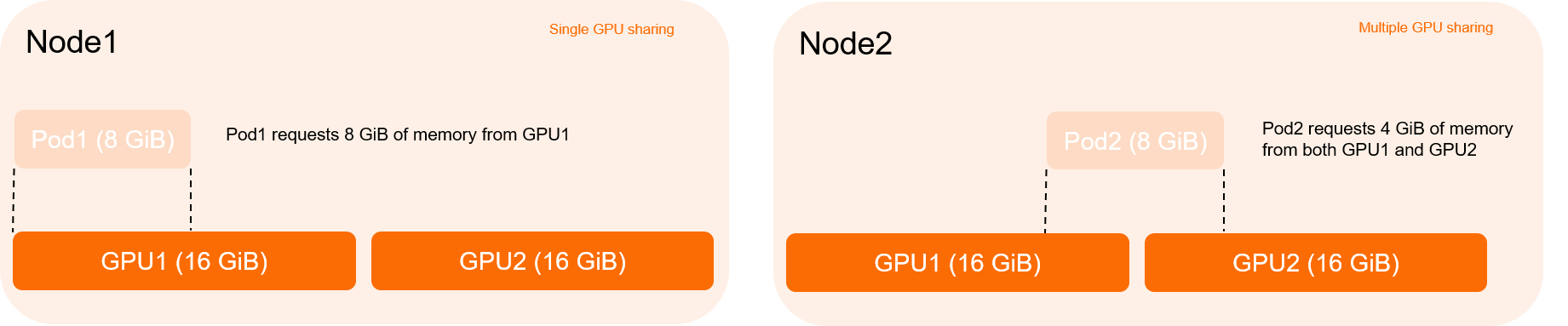
Single GPU sharing and multiple GPU sharing
Single GPU sharing: A pod can request GPU resources that are allocated by only one GPU.
Multiple GPU sharing: A pod can request GPU resources that are evenly allocated by multiple GPUs.