This topic describes how to configure scheduling properties and scheduling dependencies for a synchronization task that is scheduled by week.
Prerequisites
A zero load node named start and an ODPS SQL node named insert_data are created. For more information, see Create a workflow.
A synchronization node named write_result is created to generate a synchronization task. For more information, see Create a synchronization task.
Background information
DataWorks provides powerful scheduling capabilities that you can use to run tasks based on the time properties and scheduling dependencies of the tasks. DataWorks ensures that tens of millions of tasks can run in an accurate and punctual manner every day based on directed acyclic graphs (DAGs). DataWorks allows you to schedule tasks by minute, hour, day, week, or month. For more information, see Configure time properties.
Configure time properties
Go to the DataStudio page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
On the DataStudio page, find the workflow to which the write_result node belongs. Then, find the write_result node and double-click the node name to go to the configuration tab of the node.
On the configuration tab of the node, click Properties in the right-side navigation pane.
NoteIn a manually triggered workflow, all nodes must be manually triggered, and cannot be automatically scheduled by DataWorks.
In the Schedule section of the Properties tab, configure time properties for the node. The following table describes the parameters.
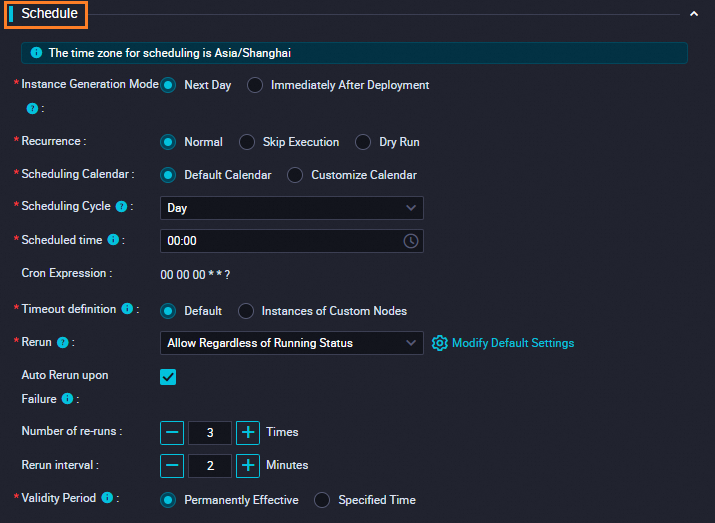
Parameter
Description
Instance Generation Mode
The mode in which instances generated for the node take effect in the production environment. Valid values: Next Day and Immediately After Deployment. For more information, see Configure immediate instance generation for a task.
Recurrence
Normal: The task on the node is run and generates data based on the settings of the scheduling cycle and scheduling time.
Skip Execution: The task on the node is scheduled based on the settings of the scheduling cycle and scheduling time. However, the status of the node is set to Freeze, and the node generates no data.
Dry Run: The task on the node is scheduled based on the settings of the scheduling cycle and scheduling time. However, the node performs a dry run and generates no data.
Scheduling Cycle
The scheduling cycle of the node. Valid values: Minute, Hour, Day, Week, Month, and Year. In this example, this parameter is set to Week, the Run Every parameter is set to Monday and Tuesday, and the Scheduled time parameter is set to
00:00. In this case, the node is scheduled to run at 00:00 every Monday and Tuesday.Cron Expression
The CRON expression of the scheduling time that you specified. You cannot change the value of this parameter.
Timeout definition
The timeout period. If the period of time for which the task on the node is run exceeds the specified timeout period, the task fails.
The timeout period applies to auto triggered task instances, data backfill instances, and test instances.
The default timeout period ranges from 72 hours to 168 hours. The system adjusts the default timeout period for a task based on system loads.
NoteYou can specify a custom timeout period that cannot exceed 168 hours.
If a task times out, the traffic and computing resources that are consumed by the task are still billed.
Rerun
Specifies whether to allow the task on the node to be rerun. Valid values: Allow Regardless of Running Status, Allow upon Failure Only, and Disallow Regardless of Running Status.
Auto Rerun upon Failure
This parameter is displayed only if you set the Rerun parameter to Allow Regardless of Running Status or Allow upon Failure Only. You can configure related settings to enable the system to rerun the task on the node after an error occurs. This parameter is not displayed if you set the Rerun parameter to Disallow Regardless of Running Status. In this case, the task on the node is not rerun after an error occurs.
Number of re-runs
The default number of times that a task on a node is rerun after the task fails to run as scheduled. This parameter is displayed only if you select the Auto Rerun upon Failure check box.
Rerun interval
The interval at which a task on a node is rerun after the task fails to run as scheduled. This parameter is displayed only if you select the Auto Rerun upon Failure check box. Valid values: 1 to 30. Default value: 30. Unit: minutes.
Validity Period
The validity period during which the task is run as scheduled. Specify the validity period based on your business requirements.
For more information about the time properties, see Configure time properties.
Configure scheduling dependencies
You can configure an ancestor node for the node. The scheduling system runs the instances that are generated for the node only after the instances that are generated for the ancestor node are successfully run, regardless of whether the scheduling time of the node arrives.
For example, you configure an ancestor node named insert_data for the current node. The instances that are generated for the current node can be run only after the instances that are generated for the insert_data node are successfully run.
Scheduling dependencies in DataWorks define the relationships between nodes in scheduling scenarios. After you configure scheduling dependencies for a node, the node starts to run only after its ancestor nodes are successfully run. After you configure scheduling dependencies for a node and the ancestor node of the node generates table data, the node cleanses the generated table data or delivers the table data that is cleansed by the ancestor node to other databases. For more information about the logic of scheduling dependencies, see Scheduling dependency configuration guide.
By default, the scheduling system creates a node that is named in the format of Workspace name_root for each workspace as the root node. If no ancestor node is configured for the current node, the current node can depend on the root node.
Commit and deploy the task
On the configuration tab of the write_result node, click the
 icon in the top toolbar to save the node.
icon in the top toolbar to save the node. Commit the task.
NoteBefore you commit the task, you must configure the Rerun and Parent Nodes parameters on the Properties tab.
Click the
 icon in the top toolbar.
icon in the top toolbar. In the Submit dialog box, configure the Change description parameter.
Click Confirm.
If you use a workspace in standard mode, the task is committed to the development environment after you click Confirm. If you want to deploy the task to the production environment for periodic scheduling, click the Deploy tab in the upper-left corner to deploy the task. For more information, see Deploy nodes.
A task must be committed to the scheduling system so that the scheduling system can generate and run instances for the task. The scheduling system runs the instances that are generated for the task at specific points in time from the next day based on the specified scheduling cycle.
NoteIf you commit a task after 23:30, the scheduling system generates and runs an instance of the task on the third day.
What to do next
Now you have learned how to configure scheduling properties and scheduling dependencies for a batch synchronization task. You can proceed with the next tutorial. In the next tutorial, you will learn how to perform O&M operations on the committed task on a regular basis and troubleshoot errors that occur on the task based on run logs. For more information, see Run a node and troubleshoot errors that occur on the node.