ApsaraDB for MongoDB replica set instances use a multi-node architecture to provide built-in high availability, automatic failover, and read scaling—no manual configuration required.
Architecture
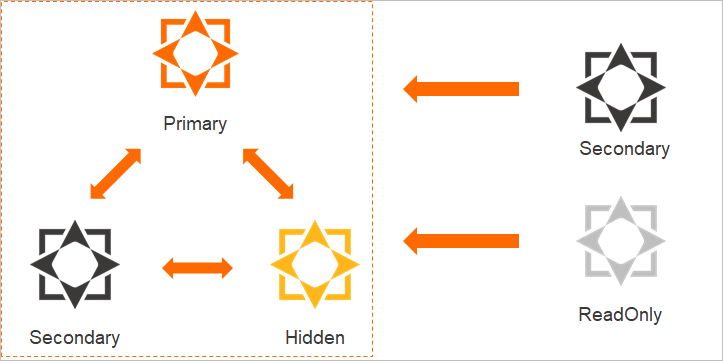
A replica set instance consists of the following nodes:
Primary node: processes all read and write requests. Each instance has exactly one primary node.
Secondary node: replicates data from the primary using oplogs. If the primary fails, a secondary is automatically elected as the new primary.
Hidden node: replicates data from the primary using oplogs. Serves as a standby that automatically replaces a failed secondary or read-only node. The hidden node is invisible to users, does not appear in the secondary node list, and cannot be elected as the primary—but still participates in elections. Each instance has exactly one hidden node.
Read-only node (optional): replicates data from whichever primary or secondary node has the lowest latency. Offloads read traffic from the primary and secondary nodes.
The term "primary and secondary nodes" covers the primary node, secondary nodes, and the hidden node.
High availability
Secondary nodes maintain a synchronized copy of the primary's data. If the primary fails, an election automatically promotes a secondary to primary—maintaining service continuity without manual intervention.
If a secondary node fails, the hidden node is automatically elected as a replacement secondary. If this operation is not automatically performed, you can manually perform this operation. If a read-only node fails, the hidden node is automatically elected as a replacement read-only node. If this operation is not automatically performed, you can manually perform this operation. In both cases, the connection string URI for that node remains unchanged after the role switch.
Each role switch may cause a transient connection interruption of up to 30 seconds. Schedule role switches during off-peak hours, or make sure your application can automatically reconnect. For details, see Switch node roles.
Read scaling
Connect to a secondary node via its connection string URI to get read-only access to the instance.
Read-only nodes extend read capacity further: they use a dedicated connection string URI that is independent of the primary and secondary nodes, making them suitable for direct connection from separate systems. When an instance has two or more read-only nodes, use the read-only connection string URI to distribute read traffic across all read-only nodes. For more information, see Read-only nodes.
Node reference
| Node | Role | Constraints |
|---|---|---|
| Primary node | Processes all read and write requests | One per instance |
| Secondary node | Replicates data from the primary via oplogs; eligible for election as primary | One or more per instance |
| Hidden node | Standby node; automatically replaces a failed secondary or read-only node | One per instance; invisible to users; cannot be elected as primary; participates in elections |
| Read-only node | Replicates from the lowest-latency primary or secondary; offloads read traffic | Optional; one or more per instance; not displayed in the secondary node list; cannot be elected as primary; does not participate in elections |
Scale out a replica set instance
Add secondary nodes or read-only nodes to increase read capacity. The hidden node count is fixed at one and cannot be changed.
This flexibility is useful for workloads with high read volume and low write volume—such as online reading platforms or order query systems—where you can add or remove secondary or read-only nodes as traffic demands change.
To change the node configuration, see Change the configurations of a replica set instance.