本文将介绍数据传输服务的整个系统架构及基本实现原理。
系统架构
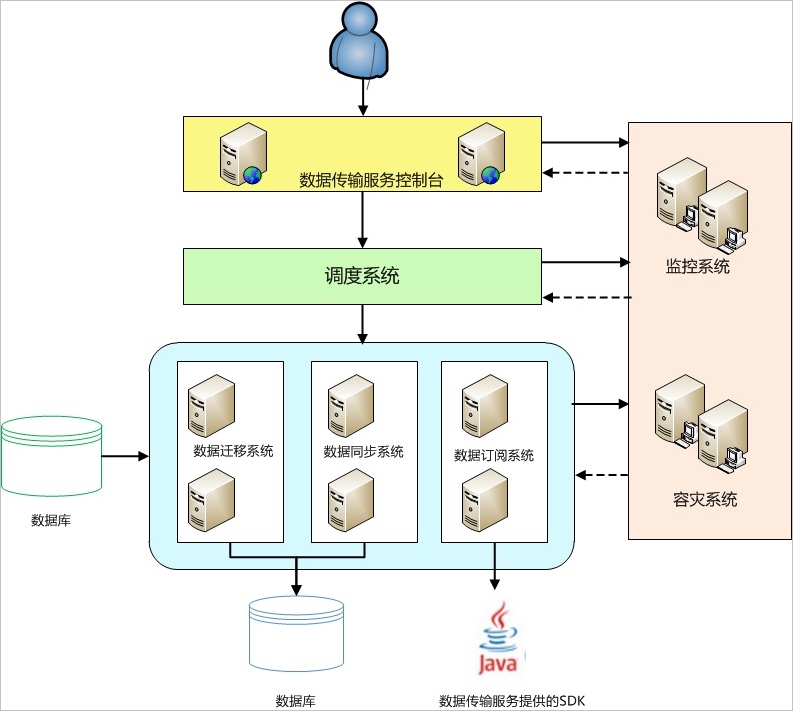
DTS系统架构特性说明
- 主备冗余
DTS的每个功能模块都部署在多个主备冗余服务器上。 容灾系统持续对每台服务器执行健康状况检查。 如果一台服务器运行异常,该服务器上的工作负载将以最小的延迟切换到运行正常的服务器。
- 接入地址动态检测
对于数据同步和数据订阅,容灾系统会检测数据源接入地址是否发生变更。 如果实例接入地址已更改,则容灾系统将重新配置数据源以保证数据连接正常运行。
数据迁移工作原理
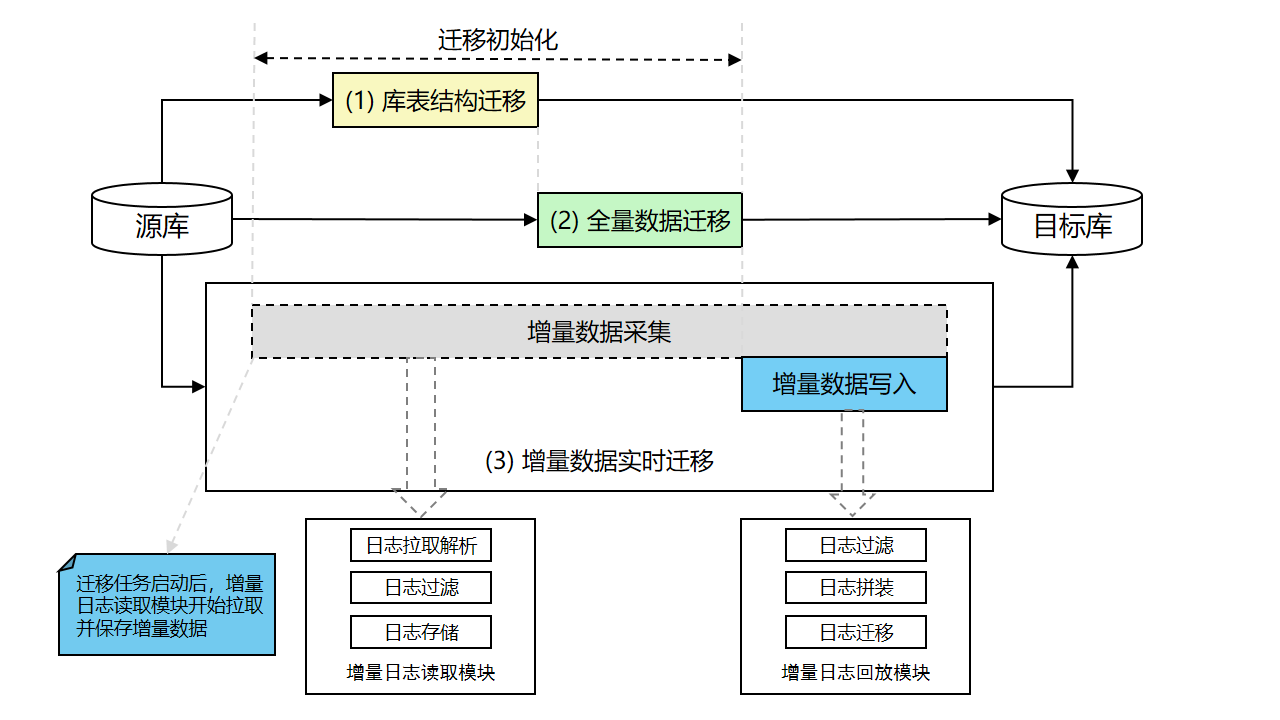
数据迁移过程包括三个阶段,即结构迁移、全量数据迁移和增量数据迁移。 如果需要在迁移期间保持源数据库的正常运行,当您在配置迁移任务时,必须将结构迁移、全量数据迁移和增量数据迁移都选为所需的迁移类型。
- 结构迁移:在迁移数据之前,DTS需要在目标数据库中重新创建数据结构。对于异构数据库之间的迁移,DTS会解析源数据库的DDL代码,将代码转换成目标数据库的语法,然后在目标数据库中重新创建结构对象。
- 全量数据迁移:在全量数据迁移阶段,DTS会将源数据库的存量数据全部迁移到目标数据库。 源数据库保持运行状态,在迁移过程中仍不断进行数据更新。 DTS使用增量数据读取模块来获取全量数据迁移过程中发生的数据更新。 当全量数据迁移开始时,增量数据读取模块将被激活。在全量数据迁移阶段,增量数据会被解析、重新格式化并存储在本地DTS服务器上。
- 增量数据迁移:当全量数据迁移完成后,DTS会检索本地存储的增量数据,重新格式化,并将数据更新应用到目标数据库中。 此过程将持续下去,直到所有正在进行的数据变更都复制到目标数据库,并且源数据库和目标数据库完全同步。
数据同步的工作原理
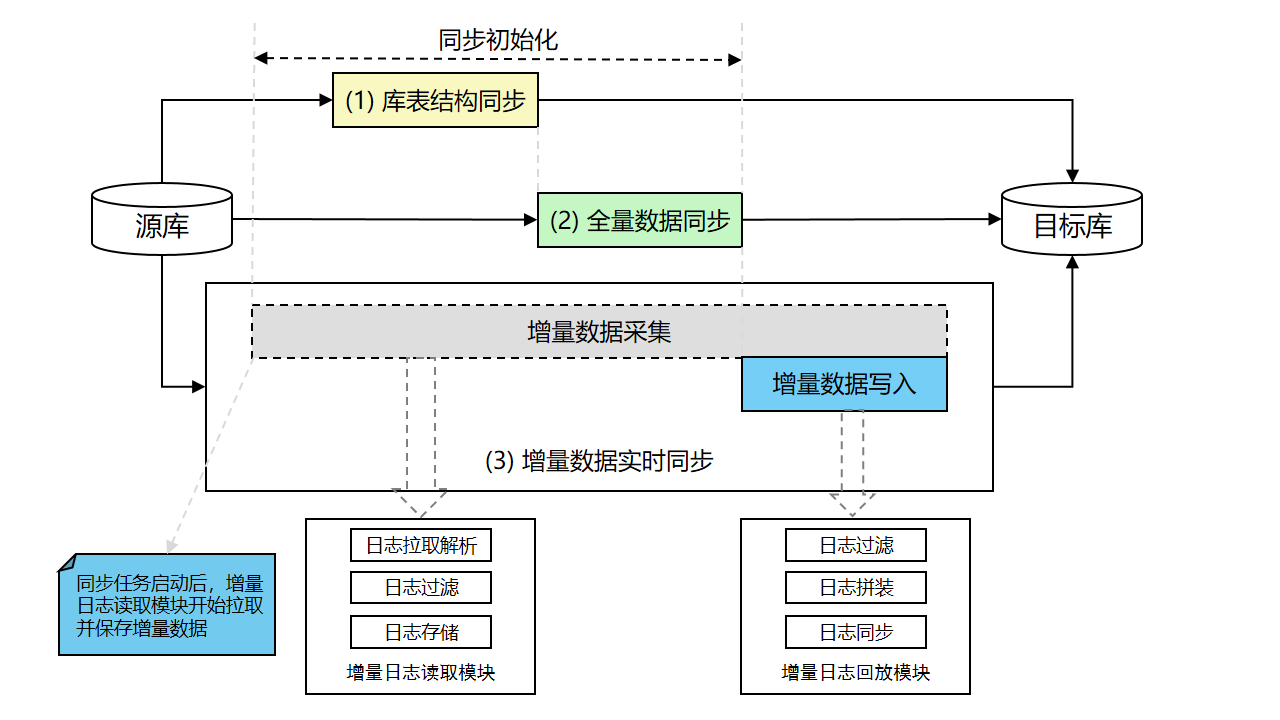
DTS可以在两个数据源之间同步正在进行的数据变更。数据同步通常用于OLTP到OLAP的数据传输。数据同步包括以下两个阶段:
- 同步初始化:DTS先开始收集增量数据,然后将源数据库的结构和存量数据加载到目标数据库。
- 数据实时同步:DTS同步正在进行的数据变更,并保持源数据库和目标数据库的同步。
为了同步正在进行的数据变更,DTS使用两个处理事务日志的模块:
- 事务日志读取模块:日志读取模块从源实例读取原始数据,经过解析、过滤及标准格式化,最终将数据在本地持久化。日志读取模块通过数据库协议连接并读取源实例的增量日志。如果源数据库为RDS MySQL,那么数据抓取模块通过Binlog dump协议连接源库。
- 事务日志应用模块:事务日志应用模块从事务日志读取模块检索并筛选数据更新,仅保留与正在同步的对象相关的数据更新,进而将数据更新应用到目标数据库。 在这个过程中,事务日志应用模块会保持事务的ACID属性,即原子性、一致性、隔离性和持久性。 事务日志读取模块和事务日志应用模块都基于冗余部署。 容灾系统检查每台服务器的健康状况。 如果发生异常,DTS将在运行正常的服务器上恢复执行事务日志。
数据订阅的工作原理
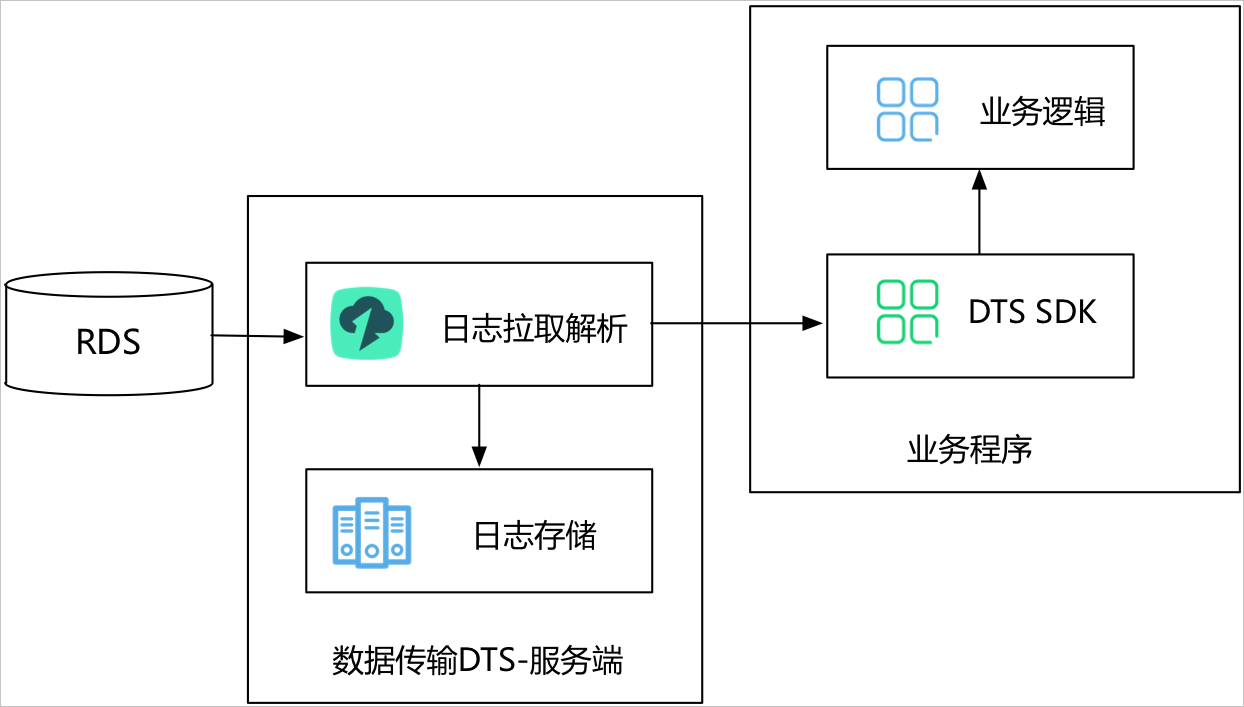
数据订阅支持实时拉取RDS实例的增量日志,用户可以通过DTS提供的SDK数据订阅服务端来订阅增量日志,同时可以根据业务需求,实现数据定制化消费。
DTS服务端的日志拉取模块主要实现从数据源抓取原始数据,通过解析、过滤、标准格式化等流程,最终将增量数据在本地持久化。
日志抓取模块通过数据库协议连接并实时拉取源实例的增量日志。例如源实例为RDS MySQL,那么数据抓取模块通过Binlog dump协议连接源实例。
日志拉取模块及下游消费SDK的高可用:
- DTS容灾系统一旦检测到日志拉取模块出现异常,就会在健康服务节点上断点重启日志拉取模块,保证日志拉取模块的高可用。
- DTS支持在服务端实现下游SDK消费进程的高可用。用户同时对一个数据订阅链路,启动多个下游SDK消费进程,服务端同时只向一个下游消费推送增量数据,当这个消费进程异常后,服务端会从其他健康下游中选择一个消费进程,向这个消费进程推送数据,从而实现下游消费的高可用。