This topic provides answers to some commonly asked questions about Elastic Container Instance, such as questions about billing, instances, containers, images, networks, and storage.
Billing
How is an elastic container instance that runs jobs billed?
After job or CronJob containers run to completion, the elastic container instances enter the Succeeded or Failed state. You are not charged for these instances regardless of whether they are deleted.
The billing duration of the elastic container instances starts when the container images start to be downloaded and the instances enter the Pending state, and ends when these instances stop running and enter the Succeeded or Failed state. For more information about the billing of the instances, see Billing of elastic container instances.
Quota limits
How do I view my vCPU quota?
The maximum number of elastic container instances that you can create in a specific region is determined based on your quota and quota usage of vCPUs within the region. If the current quota cannot meet your business requirements, go to the Quota Center console to apply for a quota increase.
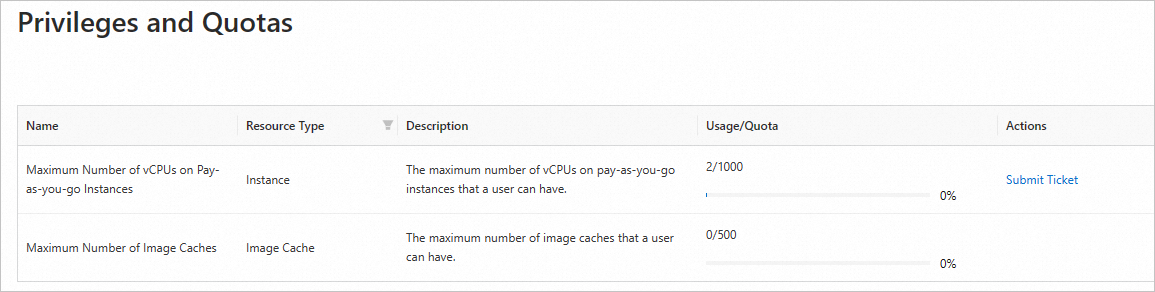
You can perform the following operations to view quotas in the Elastic Container Instance console:
Log on to the Elastic Container Instance console.
In the left-side navigation pane, click Privileges and Quotas.
The quotas and quota usage are displayed on the Privileges and Quotas page, as shown in the following figure.
How do I troubleshoot a ValueExceeded error?
If the quota is insufficient when you create an elastic container instance, a ValueExceeded error occurs. You can go to the Quota Center console to apply for a quota increase.
Instances and containers
How do I create a GPU-accelerated elastic container instance?
You can specify GPU-accelerated Elastic Compute Service (ECS) instance types to create GPU-accelerated elastic container instances. For more information, see Specify ECS instance types to create an elastic container instance.
You cannot create a GPU-accelerated elastic container instance by using the Elastic Container Instance console. However, you can create this type of instances by calling API operations.
Why do the instance specifications displayed in the Elastic Container Instance console differ from those displayed in monitoring data?
Problem description
You have created an elastic container instance that has 0.5 vCPU and 1 GiB of memory. However, the instance specifications displayed in monitoring data are 2 vCPUs and 2 GiB of memory.
Explanation
This situation is normal. Two vCPUs and 2 GiB of memory in the monitoring data are the specifications of the virtual machine, not the specifications of the elastic container instance. If you specify 0.5 vCPU and 1 GiB of memory as the specifications for an elastic container instance when you purchase the instance, the instance can use only the resources of the specified specifications.
How do I avoid an OperationDenied.NoStock error?
If resources are sold out in the current region and zone when you create an elastic container instance, an OperationDenied.NoStock error occurs. We recommend that you specify multiple instance types across multiple zones when you create elastic container instances. For more information, see Configure multiple zones to create an elastic container instance and Specify multiple specifications to create an elastic container instance.
What do I do if the "Back-off restarting failed container" event repeatedly occurs?
If a container created from a specified image does not have a daemon process, the container exits immediately after it starts. As a result, the container continuously restarts and the "Back-off restarting failed container" event keeps occurring.
Therefore, you must configure commands used to start the containers that are created from base images such as CentOS and BusyBox images. For more information, see Create an elastic container instance by using a CentOS image.
Images
Does Elastic Container Instance support private images?
Yes, Elastic Container Instance supports private images.
You can create your own images in Alibaba Cloud Container Registry. You can also build your own image repositories.
Can I update image caches?
Yes, you can update image caches.
If an image cache is in the Ready or UpdateFailed state, you can call the UpdateImageCache API operation to update the image cache, such as updating the container image, retention period, and image repository of the image cache. For more information, see UpdateImageCache.
Networking
Can I change the security group of an elastic container instance?
No, you cannot change the security group to which an elastic container instance belongs. To use an elastic container instance in a different security group, create an identical elastic container instance in that security group.
How do I access a container group from the Internet?
If you want to access the Internet from your elastic container instance or access your elastic container instance from the Internet, you must associate an elastic IP address (EIP) with the elastic container instance or attach a NAT gateway to the VPC where the elastic container instance resides. For more information, see Enable Internet access for elastic container instances.
Do elastic container instances support port mapping?
No, elastic container instances do not support port mapping.
You can use the IP address of an elastic container instance and a container port number to access the instance from a client within the same VPC. The container port is enabled by default.
To support Internet access, you must associate an EIP with the elastic container instance or attach a NAT gateway to the VPC where the elastic container instance resides. For more information, see Enable Internet access for elastic container instances.
Storage
Can an elastic container instance share a File Storage NAS (NAS) file system with an ECS instance?
Yes, an elastic container instance can share a NAS file system with an ECS instance.
You can mount the same NAS file system to the elastic container instance and the ECS instance to share data between the instances.
Do elastic container instances support data persistence?
Yes, elastic container instances support data persistence.
If an elastic container instance requires high I/O performance of the storage and needs to store large numbers of temporary files such as log files generated at runtime, we recommend that you mount an external volume to the instance. You can select disks, NAS file systems, and Object Storage Service (OSS) buckets as external volumes that are mounted to the elastic container instance based on your business requirements.
You can mount volumes to an ECI when you create the ECI. Then, you can persist data by writing the data to the volumes. For more information, see Volumes.
Others
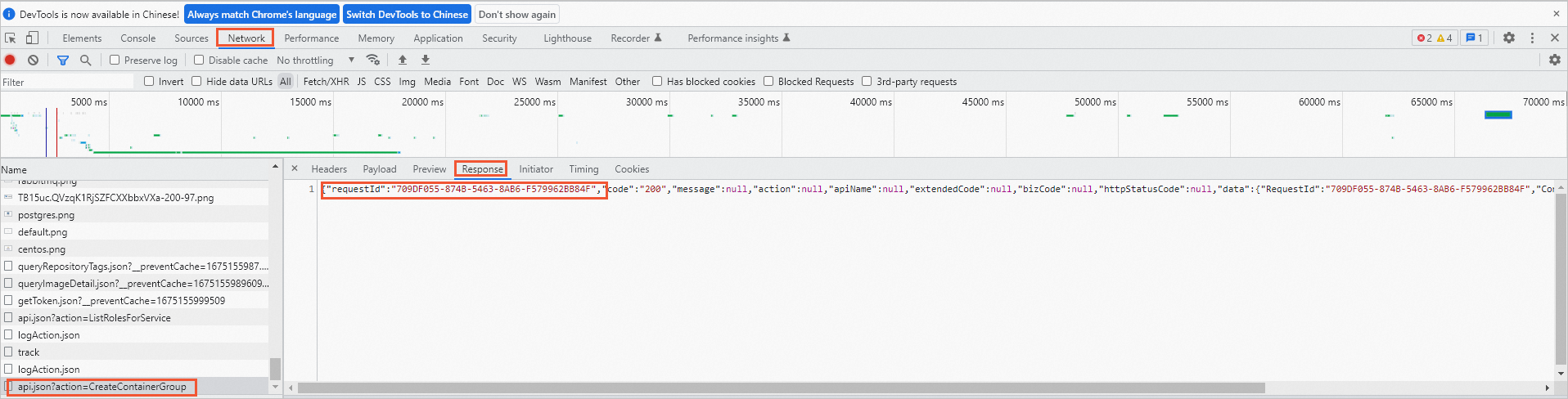
How do I obtain the request ID when I perform operations on the Elastic Container Instance console?
If an issue occurs when you use elastic container instances in the Elastic Container Instance console, you can use the developer tools of your browser to obtain the request ID. Then, you can send the request ID to Alibaba Cloud technical support to locate the issue.
Open the developer tools page of your browser.
In the following example, the Windows operating system and the Chrome browser are used. Open your browser and press F12.
NoteOn macOS, you can click the
 button in the browser and choose More Tools> Developer Tools to open the developer tools page.
button in the browser and choose More Tools> Developer Tools to open the developer tools page. On the developer tools page, click the Network tab.
In the Elastic Container Instance console, perform operations such as creating an elastic container instance.
On the Network page of the developer tools page, click the API action in the Name column.
An API action usually starts with
api.json, and theactionvalue is the name of the API operation. For example, the API action of creating an elastic container instance isapi.json?action=CreateContainerGroup.Click the Response tab to obtain the request ID.