このトピックでは、Machine Learning Designerが提供する予測コンポーネントについて説明します。 ペアの予測コンポーネントを持たない従来のデータマイニングコンポーネントを使用してモデルをトレーニングし、そのモデルを使用して予測を生成する場合は、ほとんどの場合、予測コンポーネントを選択できます。 このコンポーネントは、トレーニングされたモデルおよび予測データを入力として使用し、予測結果を生成する。
コンポーネントの設定
次のいずれかの方法を使用してコンポーネントを設定できます。
方法1: Machine Learning Designerでコンポーネントを構成する
Machine Learning Platform for AIコンソールのMachine Learning Designerの [パイプライン設定] タブでコンポーネントを設定します。
タブ | パラメーター | 説明 |
フィールド設定 | フィーチャー列 | 予測のために入力テーブルから選択されたフィーチャ列。 デフォルトでは、入力テーブルのすべての列が選択されます。 |
予約済み列 | 出力テーブルで予約する列。 評価を容易にするためにラベル列を追加することを推奨します。 | |
出力結果列 | 出力テーブルの結果列。 | |
出力スコア列 | 出力テーブルのスコア列。 | |
出力詳細列 | 出力テーブルの詳細列。 | |
スパース行列 | 入力データがスパースかどうかを指定します。 スパースデータは、キーと値のペアを使用して表示されます。 | |
KVデリミタ | キーと値を区切るために使用される区切り文字。 デフォルトでは、コロン (:) が使用されます。 | |
KVペア区切り文字 | キーと値のペアを区切るために使用される区切り文字。 デフォルトでは、コンマ (,) が使用されます。 | |
チューニング | コア | コアの数。 このパラメーターは、[コアあたりのメモリサイズ] パラメーターと一緒に使用する必要があります。 このパラメーターの値は正の整数でなければなりません。 |
コアあたりのメモリサイズ | 各コアのメモリサイズ。 このパラメーターは、Coresパラメーターと共に使用する必要があります。 単位:MB。 |
方法2: AIコマンド用の機械学習プラットフォームの実行
Machine Learning Platform for AIコマンドを使用してコンポーネントパラメーターを設定します。 SQLスクリプトコンポーネントを使用して、Machine Learning Platform for AIコマンドを実行できます。 詳細については、「SQLスクリプト」をご参照ください。 コマンドで使用するパラメーターを次の表に示します。
pai -name prediction
-DmodelName=nb_model
-DinputTableName=wpbc
-DoutputTableName=wpbc_pred
-DappendColNames=label;パラメーター | 必須 | 説明 | デフォルト値 |
inputTableName | 可 | 入力テーブルの名前。 | なし |
featureColNames | 不可 | 予測のために入力テーブルから選択されたフィーチャ列。 複数の列はコンマ (,) で区切ります。 | すべての列 |
appendColNames | 不可 | 入力テーブルから選択され、出力テーブルに追加される予測列。 | なし |
inputTablePartitions | 不可 | トレーニング用に入力テーブルから選択されたパーティション。 次の形式がサポートされています。
説明 複数のパーティションを指定する場合は、コンマ (,) で区切ります。 | フルテーブル |
outputTablePartition | 不可 | 結果が出力テーブルに含まれるパーティション。 | なし |
resultColName | 不可 | すべての可能な結果の中で最も高い確率を持つ予測結果を含む出力テーブルの列。 | prediction_result |
scoreColName | 不可 | 予測結果の確率が最も高い出力テーブルの列。 | prediction_score |
detailColName | 不可 | すべての可能な結果とその確率を含む出力テーブルの詳細列。 | prediction_detail |
enableSparse | 不可 | 入力データがスパースかどうかを指定します。 有効な値: trueとfalse。 | false |
itemDelimiter | 不可 | スパースキーと値のペアを区切るために使用される区切り文字。 | , |
kvDelimiter | 不可 | スパースキーと値を区切るために使用される区切り文字。 | : |
modelName | 可 | 入力クラスタリングモデルの名前。 | なし |
outputTableName | 可 | 出力テーブルの名前。 | なし |
ライフサイクル | 不可 | 出力テーブルのライフサイクル。 | なし |
coreNum | 不可 | コアの数。 | 自動割り当て |
memSizePerCore | 不可 | 各コアのメモリサイズ。 単位:MB。 | 自動割り当て |
例:
次のSQL文を実行してテストデータを生成します。
create table pai_rf_test_input as select * from ( select 1 as f0,2 as f1, "good" as class union all select 1 as f0,3 as f1, "good" as class union all select 1 as f0,4 as f1, "bad" as class union all select 0 as f0,3 as f1, "good" as class union all select 0 as f0,4 as f1, "bad" as class )tmp;次のコマンドを実行してモデルを構築します。 この例では、ランダムフォレストアルゴリズムが使用されます。
PAI -name randomforests -project algo_public -DinputTableName="pai_rf_test_input" -DmodelName="pai_rf_test_model" -DforceCategorical="f1" -DlabelColName="class" -DfeatureColNames="f0,f1" -DmaxRecordSize="100000" -DminNumPer="0" -DminNumObj="2" -DtreeNum="3";次のコマンドを実行して、予測コンポーネントに設定されたパラメーターを送信します。
PAI -name prediction -project algo_public -DinputTableName=pai_rf_test_input -DmodelName=pai_rf_test_model -DresultColName=prediction_result -DscoreColName=prediction_score -DdetailColName=prediction_detail -DoutputTableName=pai_temp_2283_76333_1次の図に示すように、出力結果テーブルpai_temp_2283_76333_1を表示します。
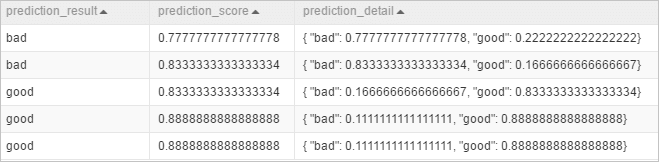
predict_result: すべての可能な結果の中で最も高い確率を持つ予測結果を含む列。
prediction_score: 予測結果の確率を含む列。
この例では、予測結果は、どちらの確率が高いかに応じて、良いか悪いかになります。 prediction_score列は、最も高い確率を含む。
prediction_detail: すべての可能な結果とその確率を含む列。