LogView records and displays the status of MaxCompute jobs. Open the LogView URL after submitting a job to monitor progress, inspect execution details, and diagnose failures. The interactive directed acyclic graph (DAG), execution playback, and Fuxi Sensor resource charts give you the visibility to identify slow tasks, locate failed instances, and analyze CPU or memory bottlenecks.
Access LogView
When you submit a MaxCompute job, the system automatically generates a URL starting with https://logview.aliyun.com/logview.
-
MaxCompute client: Copy the URL and paste it into a browser.
-
DataWorks: Click the URL directly to open the LogView page.
The LogView page has three sections:
| No. | Section |
|---|---|
| 1 | Title and functionality section |
| 2 | Basic Info section |
| 3 | Job details section |
Title and functionality section
This section shows the job ID and job name. The job ID uniquely identifies a MaxCompute job and is generated when the job is submitted. The job name appears only when the job is submitted via an SDK.
Use the icons on the right to perform the following actions:
| Icon | Action |
|---|---|
| Open the Logview_detail.txt file containing job details. The file is saved to your computer. | |
| Return to the LogView V1.0 page. | |
| Save job details as a file to your computer. |
Basic Info section
The Basic Info section shows metadata about the job.
| Parameter | Description |
|---|---|
| MaxCompute Service | The endpoint of MaxCompute on which the job runs. For more information, see Endpoints. |
| Project | The MaxCompute project the job belongs to. |
| Cloud account | The Alibaba Cloud account used to submit the job. |
| Type | The job type. Valid values: SQL, SQLRT, LOT, XLib, CUPID, AlgoTask, and Graph. |
| Status | The job status. See Job status values. |
| Start Time | The time at which the job was submitted. |
| End Time | The time at which the job completed. |
| Latency | The total run duration. |
| Progress | The current completion percentage. |
| Priority | The job priority. |
| Queue | The job's position in the resource quota group queue. |
Job status values
| Status | Description |
|---|---|
| Waiting | The job is queued in MaxCompute but has not yet been submitted to Job Scheduler. |
| Running | The job is being processed by Job Scheduler. |
| Success | The job completed successfully. |
| Failed | The job failed. |
| Canceled | The job was canceled. |
| Terminated | The job is complete. |
Job details section
The job details section contains multiple tabs. The table below maps each tab to its diagnostic purpose so you can go directly to the right view.
| Tab | When to use |
|---|---|
| Job Details | Understand execution structure; identify slow or stuck tasks by inspecting the DAG, heat charts, and instance-level status. |
| Fuxi Sensor | Analyze resource consumption — for example, investigate an out-of-memory (OOM) error or explain why a task runs slower than expected. |
| Result | View the job output on success, or the failure reason on failure. |
| SubStatusHistory | Understand what the job was doing at each stage and why it waited or failed. |
| SourceXML | Inspect raw job configuration: XML, settings, and flag values. |
| SQL Script | View the SQL script for the current task. |
| History | View the execution history of the current task. |
Job Details tab
The Job Details tab is your primary view for understanding execution structure and identifying where a job is slow or stuck.
Progress chart
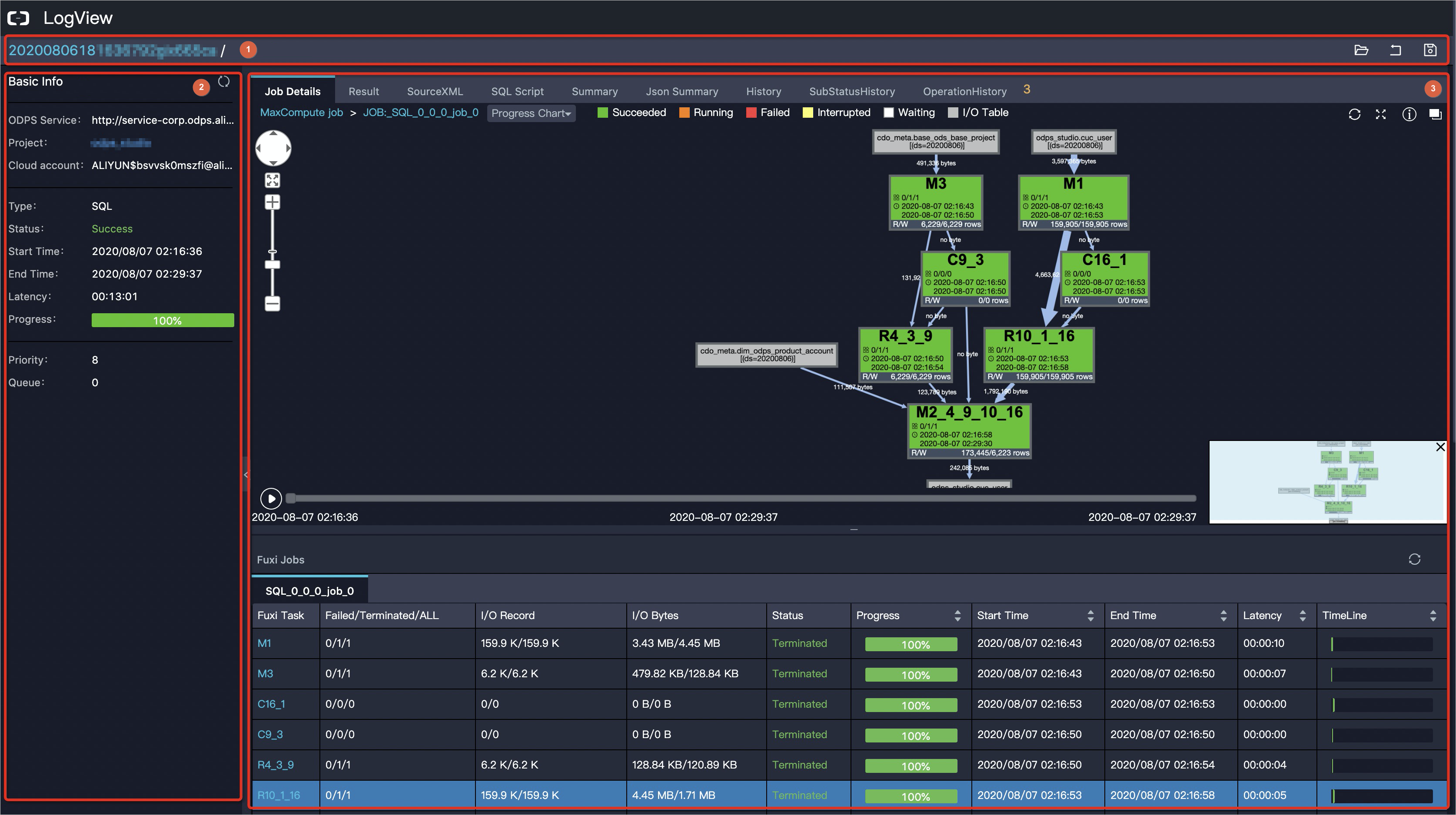
The progress chart in the upper part of the tab shows dependencies between Fuxi jobs, Fuxi tasks, and operators as an interactive DAG.
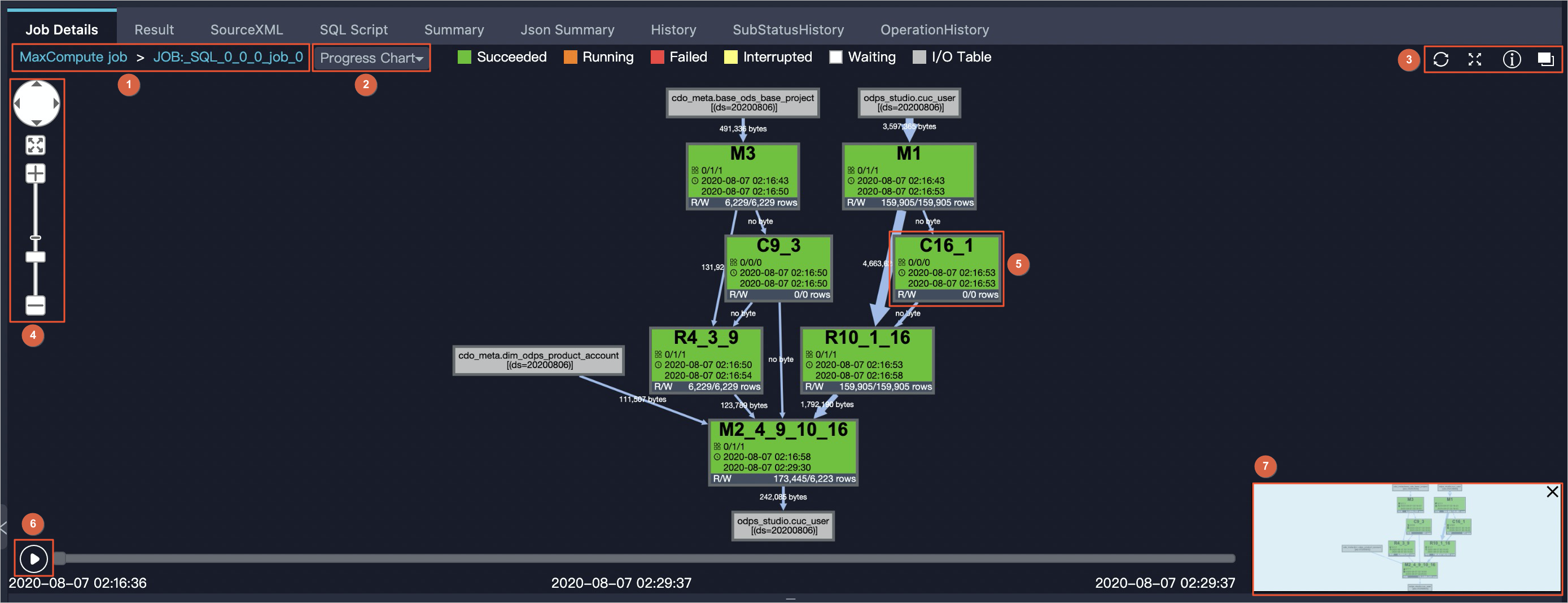
| No. | Element |
|---|---|
| 1 | Breadcrumb navigation for switching between Fuxi jobs. For example, JOB:_SQL_0_0_0_job_0 is a Fuxi job name. |
| 2 | Troubleshooting tools: Progress Chart, Input Heat Chart, Output Heat Chart, TaskTime Heart Chart, and InstanceTime Heart Chart. |
| 3 | Toolbar icons: refresh job status, zoom in or out, open MaxCompute Studio documentation, and switch to the parent level. |
| 4 | Zoom tool. |
| 5 | Fuxi tasks. See Fuxi task structure. |
| 6 | Playback controls. Click the play/stop icon to start or stop. Drag the progress bar to scrub. Start and end times appear on each side; the current playback time appears in the middle. |
| 7 | Thumbnail of the full DAG. |
-
If the job has a single Fuxi job, the chart shows dependencies among Fuxi tasks.
-
If the job has multiple Fuxi jobs, the chart shows dependencies among those Fuxi jobs.
The playback feature is not available for Fuxi tasks in the Running state. AlgoTask jobs (such as Platform for AI (PAI) jobs) contain only one Fuxi task, so no progress chart is displayed. For non-SQL jobs, only Fuxi jobs and Fuxi tasks are shown.
Fuxi task structure
A MaxCompute job consists of one or more Fuxi jobs. Each Fuxi job consists of one or more Fuxi tasks. Each Fuxi task runs across one or more Fuxi instances — more instances are added as input data volume grows.
Fuxi task prefixes indicate the task type:
| Prefix | Task type |
|---|---|
| M | Data scanning |
| R | Reduce |
| J | JOIN |
| C | Virtual node (used for branch selection only; no computation) |
Task names encode their dependencies. For example:
-
R4_3_9— task R4 can run only after tasks M3 and C9_3 complete. -
M2_4_9_10_16— task M2 can run only after tasks R4_3_9, C9_3, R10_1_16, and C16_1 complete. -
R/W on each task node shows the number of rows read and written.
Click or right-click a task node to view operator dependencies and operator graphs for that task.
Job status panel
The lower part of the Job Details tab lists Fuxi task and instance details.
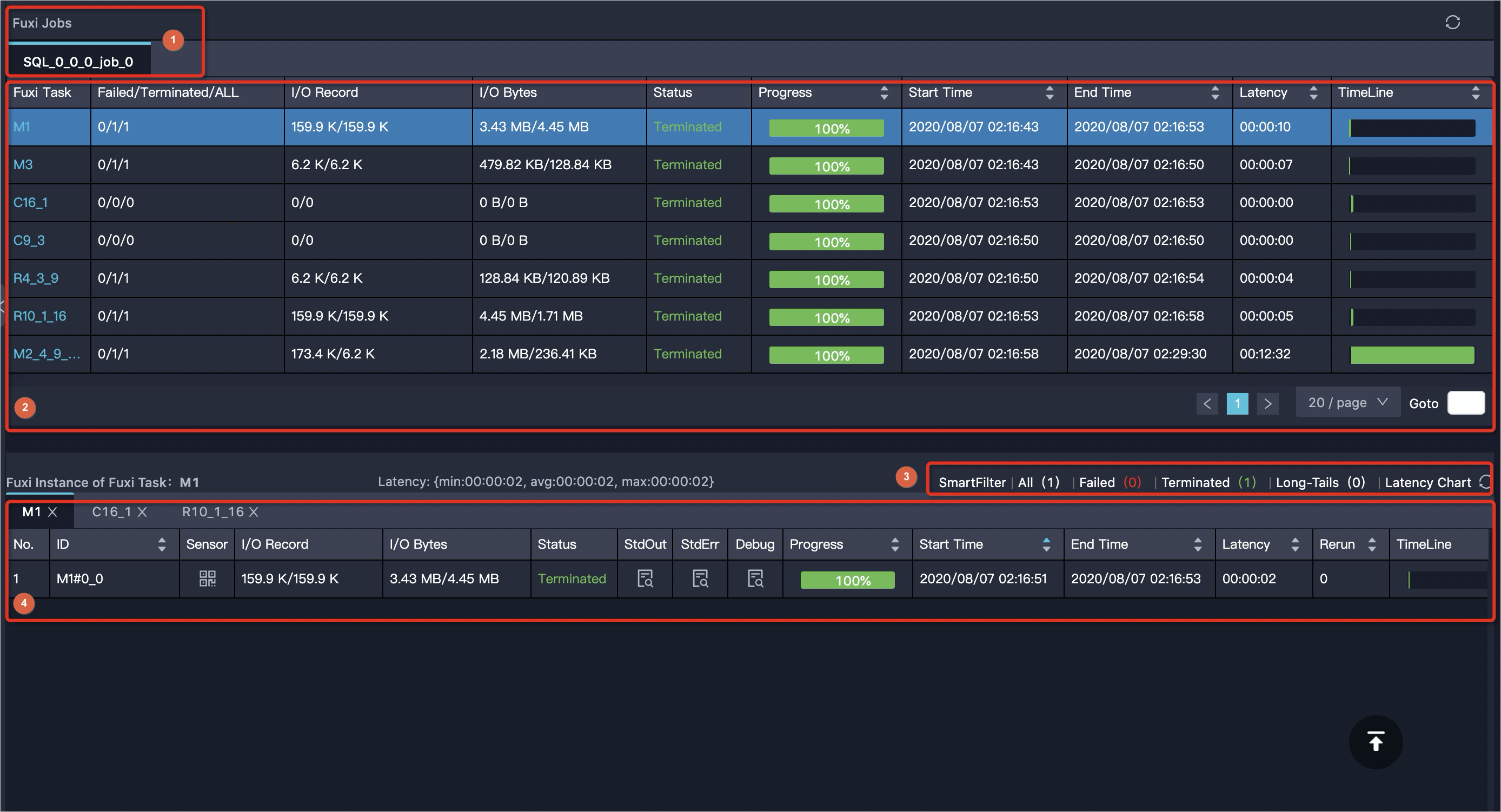
| No. | Element |
|---|---|
| 1 | The Fuxi Jobs tab for switching between Fuxi jobs. |
| 2 | Fuxi task details. Click a Fuxi task to display information about its instances. By default, the instances of the first Fuxi task of the first Fuxi job are shown. For AlgoTask jobs and jobs running in the Cupid console, a Sensor column appears — click the sensor icon to view CPU and memory information for that instance. |
| 3 | Instance groups by status. Click the count next to Failed to inspect failed instances. |
| 4 | Individual Fuxi instances and their details. |
Fuxi instance IDs follow the format M1#0_0:
-
The first number is the auto-increment instance ID.
-
The second number is the rerun count (0 means the Fuxi task fails to rerun).
Each instance exposes:
-
StdOut / StdErr: output and error messages, downloadable.
-
Debug: tools for debugging and troubleshooting.
If a Fuxi task shows the Interrupted state, the task may be rerun. In this case, the Progress column reflects only the rerun progress, so a task may show less than 100% even though the overall job succeeds. This is expected behavior.
Limits on Fuxi instances
The number of Fuxi instances is limited to 1 when any of the following conditions apply to the SQL statement:
-
The
LIMITclause is used. -
A window function is used without the
PARTITION BY KEYclause. -
An aggregate function is used without the
GROUP BY KEYclause. -
A JOIN operation has no equi-join key.
-
The
ORDER BYclause is used.
Fuxi Sensor tab
Use Fuxi Sensor to analyze resource consumption — for example, to investigate an out-of-memory (OOM) error or understand why a task is running slower than expected.
Fuxi Sensor shows CPU utilization and memory usage for individual Fuxi instances.
Fuxi Sensor is available in the China (Chengdu), China (Shenzhen), China (Shanghai), China (Hangzhou), China (Zhangjiakou), and China (Beijing) regions.
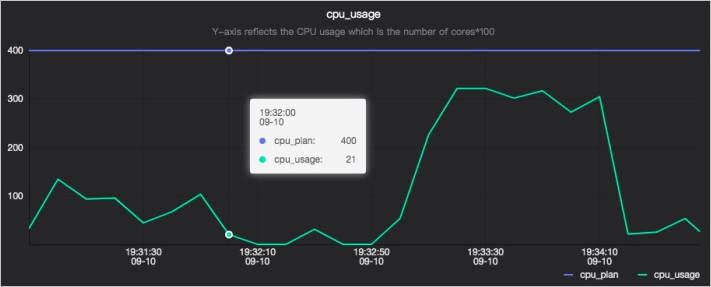
CPU utilization
The cpu_usage chart has two lines:
-
cpu_plan: the number of CPUs requested. -
cpu_usage: the number of CPUs actually used.
On the y-axis, a value of 400 represents four processors. Adjust requested CPUs by changing the number of processors; the usable CPU count cannot be configured separately.
Memory usage
The mem_usage chart has two lines:
-
mem_plan: the amount of memory requested. -
mem_usage: the amount of memory actually used.
mem_usage is the sum of two components:
| Component | Description | Reclaimable |
|---|---|---|
| RSS (Resident Set Size) | Memory allocated after kernel page faults, used when malloc is called for non-file mappings. |
No |
| PageCache | Memory the kernel uses to cache files for read and write operations (for example, log files). | Yes |
The tab provides three sub-charts for memory analysis:
-
Memory details
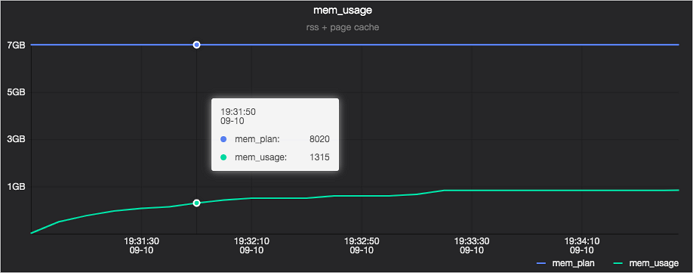
-
RSS usage
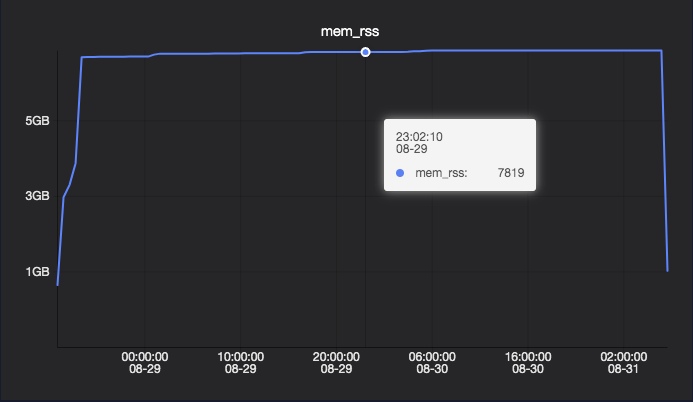
-
PageCache usage
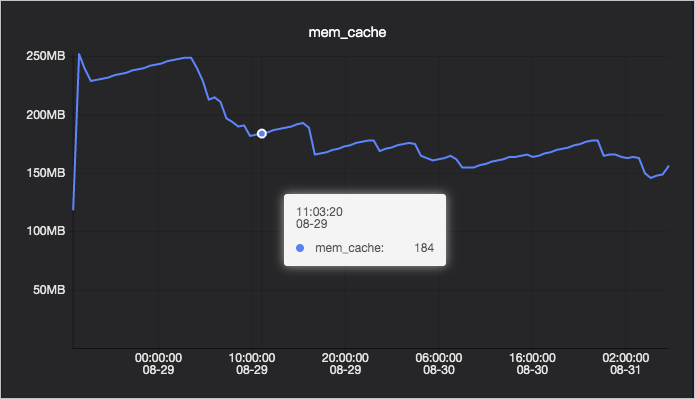
Result tab
The Result tab displays different content depending on the job outcome:
-
Success: the job result is shown.
-
Failed: the failure reason is shown.
To disable automatic result display, run:
setproject odps.forbid.fetch.result.by.bearertoken=true;To change the result display format, set odps.sql.select.output.format:
-- Display results in CSV format
set odps.sql.select.output.format=csv;
-- Display results in plain text format
set odps.sql.select.output.format=HumanReadable;SubStatusHistory tab
The SubStatusHistory tab shows the status progression of the current task. Use this tab to understand what the job was doing at each stage and why it may have waited or failed.
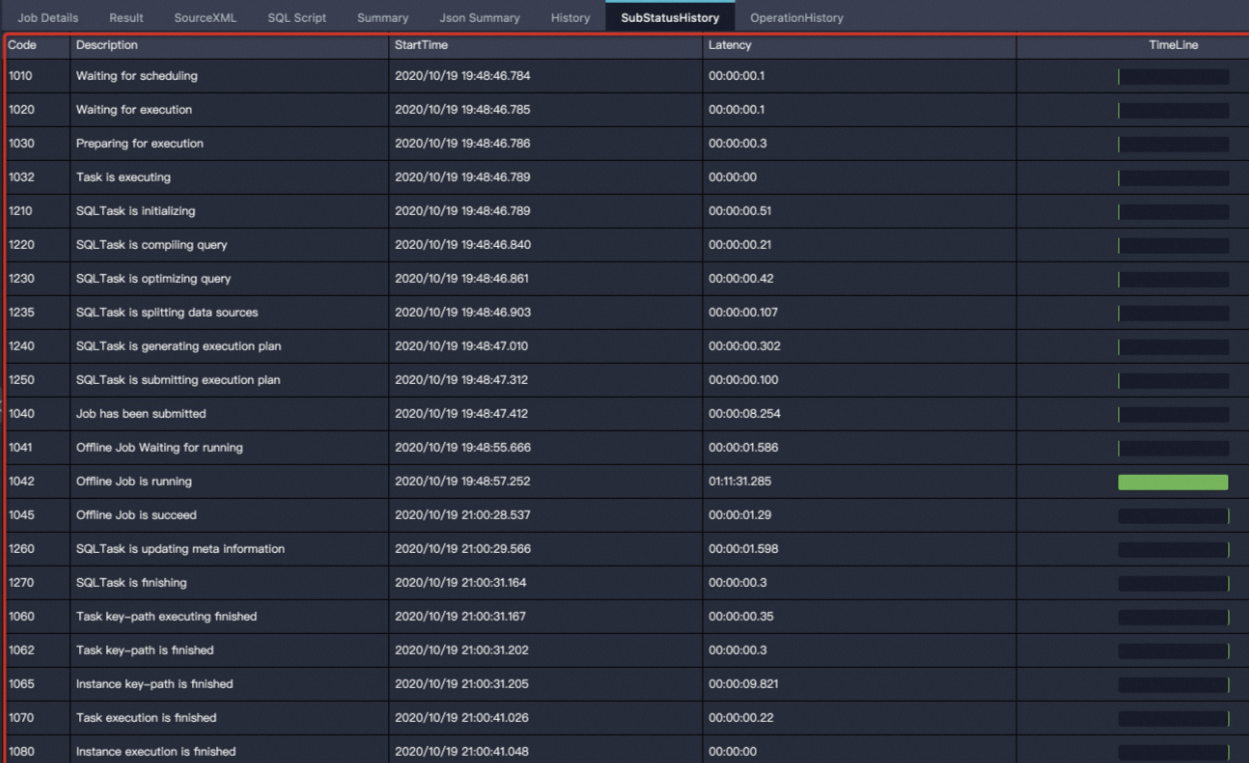
| Status code | Description |
|---|---|
| Waiting for scheduling | The job was submitted and is waiting for the MaxCompute framework to schedule it. The wait is typically short. |
| Waiting for cluster resource | The MaxCompute framework detected insufficient resources in the Fuxi computing cluster. |
| Waiting for concurrent task slot | Project-level throttling was triggered. The project has a limit on the number of SQL tasks that can run simultaneously. |
| Waiting for data replication | The job is waiting for data replication to complete. |
| Waiting for execution slot | System-level throttling was triggered. |
| Waiting for cleaning up of previous task attempt | The job is waiting for cleanup of a previous task attempt. |
| Waiting for execution | The job is waiting to be distributed from the parent process queue to a child process. The wait is typically short. |
| Preparing for execution | The job is being distributed to a child process. If the child process is abnormal, this phase may take longer. |
| Task is executing | The job is running in the MaxCompute framework. |
| SQLTask is initializing | The SQL task is initializing. |
| SQLTask is compiling query | The SQL task is being compiled. |
| SQLTask is optimizing query | The SQL task is optimizing the query plan. For complex execution plans, this phase may take longer. If optimization takes an unusually long time, an error may occur. |
| SQLTask is splitting data sources | The SQL task is splitting data sources for optimization. |
| SQLTask is generating execution plan | The SQL task is generating the execution plan. A long duration here may indicate that data is being read from an excessive number of partitions or small files. |
| SQLTask is submitting execution plan | The SQL task is submitting the execution plan. |
| Job has been submitted | The job has been submitted to the computing cluster. |
| Offline Job Waiting for running | The job was submitted to the Fuxi cluster when resources appeared available, but resources were unavailable after submission. The job is waiting for resources. This status appears only once. |
| Offline Job is running | A running Fuxi job has insufficient resources — for example, because higher-priority jobs preempted them. Some Fuxi instances are in the ready state and waiting to run. |
| Offline Job is failed | The Fuxi job failed. |
| Offline Job is succeed | The Fuxi job completed successfully. |
| SQLTask is updating meta information | The SQL task is updating metadata and generating dynamic partitions. This process can be time-consuming. |
| SQLTask is finishing | The SQL task is finishing. |
| Online Job is cancelled by fuxi | The job in service mode was canceled. |
| Task rerun | The job is rerunning. A job in service mode may fail and switch to offline mode, or data may be replicated across clusters. |
| Online Job Waiting for running | The job in service mode is waiting to run. |
| Online Job is running | The job in service mode is running. |
| Online Job is failed | The job in service mode failed. |
| Online Job is succeed | The job in service mode completed successfully. |
| Online Job is cancelled by fuxi | The job in service mode was canceled. |
| Task key-path executing finished | The key execution path of the job is complete, but data such as DetailStatus has not yet been generated. |
| Task key-path is finished | The key execution path of the job is complete. |
| Instance key-path is finished | The key execution path of the instance is complete. |
| Task execution is finished | The job is complete and DetailStatus has been generated. |
| Instance execution is finished | The job is complete. |
| Execution failed | The job failed. |
SourceXML tab
The SourceXML tab has three sub-tabs:
| Sub-tab | Content |
|---|---|
| XML | Job levels and task information in XML format. |
| Settings | The current task's configuration settings. |
| Command | The current task's flag settings. |
SQL Script tab
The SQL Script tab shows the SQL script for the current task.
History tab
The History tab shows the execution history of the current task.