This topic describes the main components of PolarDB for PostgreSQL(Compatible with Oracle).
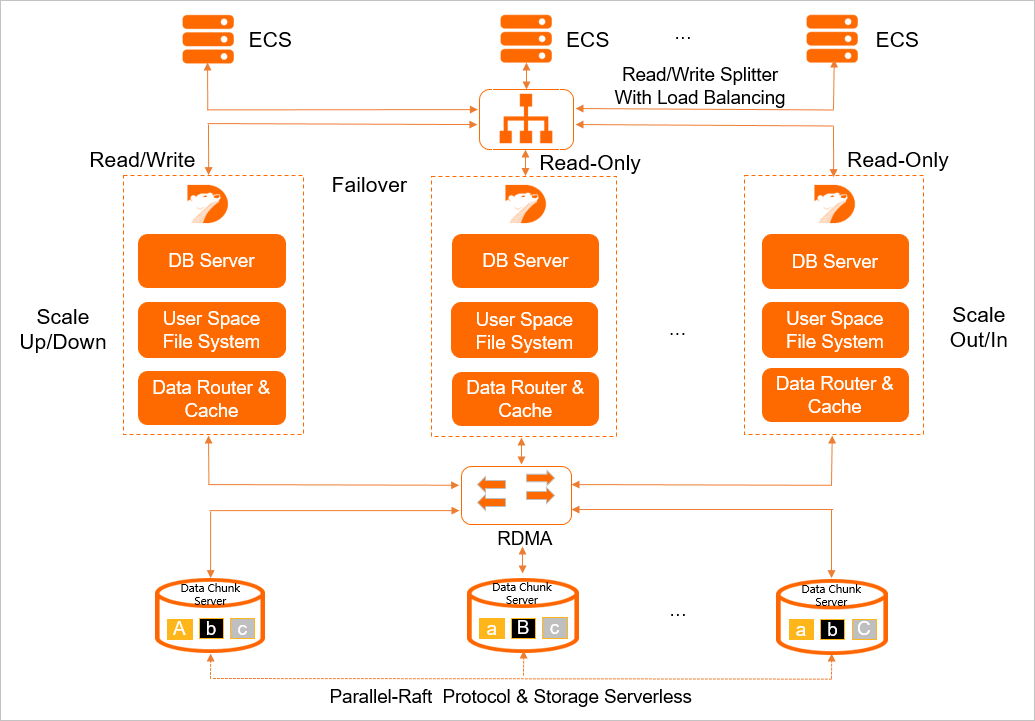
DB Server
The database server is Polar DataBase, which is PolarDB for short. In PolarDB clusters, instance roles are classified to three types: primary, standby, and replica. Primary instances are read/write instances that allow you to read or write data. Replica instances are read-only instances that allow you to only read data. You cannot modify data on replica instances by using background threads. Primary and replica instances are deployed based on the shared everything architecture. This indicates that the primary and replica instances share the same data file and the same log file at the data storage layer. Standby nodes have a separate data file and a separate log file. Standby nodes are used for disaster recovery at the data center level, and are used to create read-only instances across zones. You do not need to replicate data when you add read-only instances. You can create read-only instances at a high speed and a low cost. You need only to pay for the relevant compute nodes. In Alibaba Cloud, the standby and replica nodes are called read-only nodes, and the primary nodes are also known as the master nodes.
User Space File System
The user space file system is Polar File System, which is PolarFS for short. Database instances of multiple hosts need to access the same data file that is stored on block storage. However, the traditional file systems such as ext4 cannot be mounted at multiple mount points. To solve this problem, the PolarDB team has developed PolarFS, a dedicated file system in user mode. PolarFS provides common APIs for your to read, write, and view files. PolarFS supports data reads and writes in a non-cached way similar to O_DIRECT. PolarFS also provides features such as atomic writes on data pages and I/O priority. This ensures high performance of the databases that use these APIs at the upper layer. Traditional file systems are embedded in the kernels of operating systems. Therefore, each time you perform read and write operations on system files, the file system runs in kernel mode first. After the operations are completed, the file system runs in user mode. This causes low efficiency. PolarFS is compiled in the form of a function library in PolarDB. Therefore, PolarFS always runs in user mode. This reduces the overhead that is generated by switching the mode of the operating system.
Data Router & Cache
The data router & cache is Polar Store Client, of which the alias is PolarSwitch. After PolarFS receives read and write requests, PolarFS sends the data to PolarSwitch by using shared memory. PolarSwith is a background daemon process for the hosts of compute nodes. PolarSwith receives the requests to read and write data in block storage from all the instances and tools on the hosts. PolarSwith performs simple data aggregation and then distributes the results to the daemon processes on the relevant storage nodes.
Data Chunk Server
The data chunk server is Polar Store Server, of which the alias is ChunkSever. The preceding three components run on compute nodes, but Polar Store Server runs on storage nodes. Polar Store Server is used for reading data blocks. The size of each data block is 10 GB. Each data block has three replicas that are stored on three different storage nodes. The system returns a success message to the client only after the data is written to two of the three replicas. Polar Store Server supports high availability of data blocks. If a data block becomes unavailable, the data block can be restored within seconds and the upper layers are unaware of the failure. Polar Store Server uses a technology similar to copy-on-write so that snapshots can be created within seconds. Therefore, full data backups can be completed within seconds for databases regardless of the size of the data at the underlying layer. PolarDB supports disk space up to 100 TB. Compute nodes and storage nodes are communicated by using 25 Gbit/s remote direct memory access (RDMA). This prevents data transmission bottlenecks.