This topic describes how to use MirrorMaker 2 on Kafka Connect (Kafka MM2) to synchronize data across clusters.
Background information
Scenarios
Kafka MM2 is suitable for the following scenarios:
- Remote data synchronization: You can use Kafka MM2 to synchronize data among clusters in different regions.
- Disaster recovery: You can use Kafka MM2 to build a disaster recovery architecture that consists of primary and secondary clusters in different data centers. Data in the two clusters can be synchronized in real time. If one cluster becomes unavailable, you can transfer applications in the cluster to a different cluster. This ensures geo-disaster recovery.
- Data migration: In scenarios such as cloud migration of businesses, hybrid clouds, and cluster upgrades, data needs to be migrated from the original cluster to a new cluster. You can use Kafka MM2 to migrate data to ensure business continuity.
- Data aggregation: You can use Kafka MM2 to synchronize data from multiple Kafka sub-clusters to a Kafka central cluster. This way, data can be aggregated.
Features
As a data replication tool, Kafka MM2 provides the following features:
- Replicates the data and configuration information of topics.
- Replicates the offset information of consumer groups and the consumed topics.
- Replicates access control lists (ACLs).
- Automatically detects new topics and partitions.
- Provides Kafka MM2 metrics.
- Provides high-availability architectures that are horizontally scalable.
Job execution methods
Kafka MM2 jobs can be run in the following three methods:
- Run Kafka MM2 jobs in an existing Kafka Connect cluster in Distributed mode. This method is recommended. You can use the features described in this topic to manage Kafka MM2 jobs.
- Use the driver program to manage all Kafka MM2 jobs. For more information, see Deploy MM2 on a dedicated cluster to synchronize data across clusters.
- Run a single MirrorSourceConnector job, which is suitable for test scenarios.
Note We recommend that you use the first method. If you use this method, you can use the reset service provided by the Kafka Connect cluster to manage Kafka MM2 jobs.
For more information about Kafka MM2, see Apache Kafka documentation.
Prerequisites
The source Kafka cluster named emrsource and the destination Kafka cluster named emrdest are created. Kafka is selected as Optional Services (Select One At Least) when the clusters are created. For more information, see Create a cluster.Note In this topic, the E-MapReduce (EMR) versions of the source and destination clusters are V3.42.0. Both clusters are of the DataFlow type and reside in the same virtual private cloud (VPC).
Limits
The Kafka version of the destination cluster must be 2.12_2.4.1 or later.
Procedure
Step 1: Create a Kafka Connect cluster in the destination Kafka cluster
- Create a node group. On the Nodes page of the emrdest cluster in the EMR console, create a node group.
- Scale out the node group.
- Check the status of the Kafka Connect cluster to ensure that the cluster is running.
- In the Components section, check the status of the KafkaConnect to ensure the component is running.
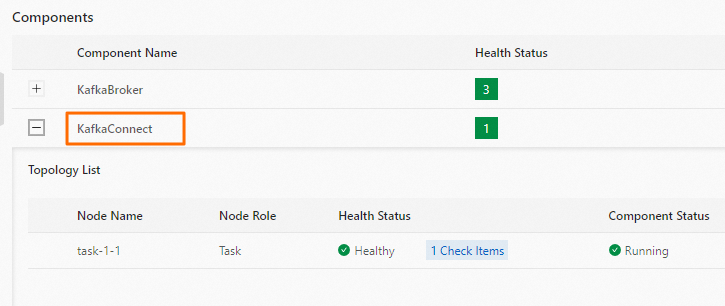
- In the Components section, check the status of the KafkaConnect to ensure the component is running.
- Use Secure Shell (SSH) to log on to the emrdest cluster. For more information, see Log on to a cluster.
- Run the following command to check the status of the reset service provided by the Kafka Connect cluster:
curl -X GET http://task-1-1:8083| jq .Information similar to the following output is returned:% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 91 100 91 0 0 13407 0 --:--:-- --:--:-- --:--:-- 15166 { "version": "2.4.1", "commit": "42ce056344c5625a", "kafka_cluster_id": "6Z7IdHW4SVO1Pbql4c****" }
Step 2: Use the Kafka MM2 connector
- Prepare the configuration files of the Kafka MM2 connector. The following files are included:
- The configuration file of MirrorSourceConnectorIn this example, the file name is mm2-source-connector.json. The following sample code describes the content of the file. Modify the parameters in the file as required. For more information, see KIP-382: MirrorMaker 2.0.
{ "name": "mm2-source-connector", "connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector", "clusters": "emrsource,emrdest", "source.cluster.alias": "emrsource", "target.cluster.alias": "emrdest", "target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092", "source.cluster.bootstrap.servers": "10.0.**.**:9092", "topics": "^foo.*", "tasks.max": "4", "key.converter": " org.apache.kafka.connect.converters.ByteArrayConverter", "value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter", "replication.factor": "3", "offset-syncs.topic.replication.factor": "3", "sync.topic.acls.interval.seconds": "20", "sync.topic.configs.interval.seconds": "20", "refresh.topics.interval.seconds": "20", "refresh.groups.interval.seconds": "20", "consumer.group.id": "mm2-mirror-source-consumer-group", "producer.enable.idempotence":"true", "source.cluster.security.protocol": "PLAINTEXT", "target.cluster.security.protocol": "PLAINTEXT" }Note Parameters in the sample code:source.cluster.bootstrap.servers: the Kafka service endpoint in the emrsource cluster. Make sure that the emrsource cluster and the Kafka Connect cluster can be connected.topics: The topics to be replicated. In this example, topics whose names start with foo are to be replicated.
- The configuration file of MirrorCheckpointConnectorIn this example, the file name is mm2-checkpoint-connector.json. The following sample code describes the content of the file. Modify the parameters in the file as required. For more information, see KIP-382: MirrorMaker 2.0.
{ "name": "mm2-checkpoint-connector", "connector.class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector", "clusters": "emrsource,emrdest", "source.cluster.alias": "emrsource", "target.cluster.alias": "emrdest", "target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092", "source.cluster.bootstrap.servers": "10.0.**.**:9092", "tasks.max": "1", "key.converter": " org.apache.kafka.connect.converters.ByteArrayConverter", "value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter", "replication.factor": "3", "checkpoints.topic.replication.factor": "3", "emit.checkpoints.interval.seconds": "20", "source.cluster.security.protocol": "PLAINTEXT", "target.cluster.security.protocol": "PLAINTEXT" } - The configuration file of MirrorHeartbeatConnectorIn this example, the file name is mm2-heartbeat-connector.json. The following sample code describes the content of the file. Modify the parameters in the file as required. For more information, see KIP-382: MirrorMaker 2.0.
{ "name": "mm2-heartbeat-connector", "connector.class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector", "clusters": "emrsource,emrdest", "source.cluster.alias": "emrsource", "target.cluster.alias": "emrdest", "target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092", "source.cluster.bootstrap.servers": "10.0.**.**:9092", "tasks.max": "1", "key.converter": " org.apache.kafka.connect.converters.ByteArrayConverter", "value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter", "replication.factor": "3", "heartbeats.topic.replication.factor": "3", "emit.heartbeats.interval.seconds": "20", "source.cluster.security.protocol": "PLAINTEXT", "target.cluster.security.protocol": "PLAINTEXT" }
- The configuration file of MirrorSourceConnector
- Use MirrorSourceConnector.
- Use MirrorCheckpointConnector.
- Use MirrorHeartbeatConnector.
- Run the following command to view topics related to Kafka MM2 in the emrdest cluster.
kafka-topics.sh --list --bootstrap-server core-1-1:9092In this example, you can view the following topics:- Topics whose names start with foo and reside in the emrsource cluster. The topics are created by MirrorSourceConnector.
The topics are existing topics in the emrsource cluster and are to be replicated.
- The emrsource.checkpoints.internal topic that is created by MirrorCheckpointConnector and used to store the offset information.
- The heartbeats topic created by MirrorHeartbeatConnector.
- Topics whose names start with foo and reside in the emrsource cluster. The topics are created by MirrorSourceConnector.