This topic describes how to use DataWorks Data Integration to migrate data from a Kafka cluster to MaxCompute.
Prerequisites
The MaxCompute and DataWorks services are activated. For more information, see Activate MaxCompute and DataWorks.
A MaxCompute data source is added. For more information, see Add a MaxCompute data source.
A workflow is created in your workspace in the DataWorks console. In this example, a workflow is created in a workspace that is in basic mode. For more information, see Create a workflow.
A Kafka cluster is created.
Before you migrate data from the Kafka cluster to MaxCompute, make sure that the Kafka cluster can work as expected. In this topic, Alibaba Cloud E-MapReduce (EMR) is used to create a Kafka cluster. For more information, see Overview.
In this example, the following configurations are used for the EMR Kafka cluster:
EMR version: V3.12.1
Cluster type: Kafka
Software: Ganglia 3.7.2, ZooKeeper 3.4.12, Kafka 2.11-1.0.1, and Kafka-Manager 1.3.X.XX
The EMR Kafka cluster is deployed in a virtual private cloud (VPC) in the China (Hangzhou) region. The Elastic Compute Service (ECS) instances in the master node group of the EMR Kafka cluster are configured with public and private IP addresses.
Background information
Kafka is a distributed middleware that is used to publish and subscribe to messages. Kafka is widely used because of its high performance and high throughput. Kafka can process millions of messages per second. Kafka is suitable for processing streaming data and is mainly used in scenarios such as user behavior tracing and log collection.
A typical Kafka cluster contains several producers, brokers, consumers, and a ZooKeeper cluster. A Kafka cluster uses ZooKeeper to manage configurations and coordinate services in the cluster.
A topic is a collection of messages that are most commonly used in a Kafka cluster, and is a logical concept for message storage. Topics are not stored on physical disks. Messages in each topic are stored on the disk of each node in the cluster by partition. Multiple producers can publish messages to a topic, and multiple consumers can subscribe to messages in a topic.
When a message is stored to a partition, the system allocates an offset to the message. The offset is a unique ID of the message in the partition. The offsets of messages in each partition start from 0.
Step 1: Prepare test data in the EMR Kafka cluster
You must prepare test data in the EMR Kafka cluster. To ensure that you can log on to the master node of the EMR Kafka cluster and that MaxCompute and DataWorks can communicate with the master node, you must configure a security group rule for the master node of the EMR Kafka cluster to allow requests on TCP ports 22 and 9092.
Log on to the master node of the EMR Kafka cluster.
Log on to the EMR console.
In the left-side navigation pane, click EMR on ECS.
On the EMR on ECS page, find the cluster in which you want to prepare test data and click the name of the cluster in the Cluster ID/Name column.
On the details page of the cluster, click the Nodes tab. On the Nodes tab, find the IP address of the master node and use the IP address to remotely log on to the master node in SSH mode.
Create a test topic.
Run the following command to create a test topic named testkafka:
kafka-topics.sh --zookeeper emr-header-1:2181/kafka-1.0.1 --partitions 10 --replication-factor 3 --topic testkafka --createWrite test data to the test topic.
Run the following command to simulate a producer to write data to the testkafka topic. Kafka is used to process streaming data. You can continuously write data to the topic in the Kafka cluster. To ensure that test results are valid, we recommend that you write more than 10 data records to the topic.
kafka-console-producer.sh --broker-list emr-header-1:9092 --topic testkafkaTo simulate a consumer to check whether data is written to the topic in the Dataflow Kafka cluster, open another SSH window and run the following command. If the written data appears, the data is written to the topic.
kafka-console-consumer.sh --bootstrap-server emr-header-1:9092 --topic testkafka --from-beginning
Step 2: Create a table in DataWorks
Create a table in DataWorks to receive data from the EMR Kafka cluster.
Go to the DataStudio page.
Log on to the DataWorks console.
In the left-side navigation pane, choose .
On the DataStudio page, select a workspace from the drop-down list and click Go to Data Development.
Right-click Workflow, Select .
In the Create Table dialog box, enter the name of the table that you want to create in the Name field and click Create.
NoteThe table name must start with a letter and cannot contain Chinese or special characters.
If multiple MaxCompute data sources are associated with DataStudio, you must select the MaxCompute data source that you want to use from the Engine Instance drop-down list.
On the table editing page, click DDL Statement.
In the DDL dialog box, enter the following table creation statement and click Generate Table Schema.
CREATE TABLE testkafka ( key string, value string, partition1 string, timestamp1 string, offset string, t123 string, event_id string, tag string ) ;Each column in the table that is created by using the preceding statement corresponds to a column from which Kafka Reader reads data.
__key__: the key of a Kafka message.
__value__: the complete content of a Kafka message.
__partition__: the partition to which a Kafka message belongs.
__headers__: the header of a Kafka message.
__offset__: the offset of a Kafka message.
__timestamp__: the timestamp of a Kafka message.
You can specify a custom column. For more information, see Kafka Reader.
Click commit to the production environment and confirm.
Step 3: Synchronize the data
Create an exclusive resource group for Data Integration.
Kafka Reader cannot run on a shared resource group of DataWorks as expected. You must use an exclusive resource group for Data Integration to synchronize the data. For more information about how to create an exclusive resource group for Data Integration, see Create and use an exclusive resource group for Data Integration.
Create a data synchronization node.
Go to the DataStudio page. In the left-side navigation pane of the DataStudio page, click Scheduled Workflow, right-click the name of the desired workflow, and then choose .
In the Create Node dialog box, configure the Name parameter and click Confirm.
In the top navigation bar, choose
 icon.
icon.In script mode, click
 icon.
icon.Configure the script. The following sample code provides an example of a script.
{ "type": "job", "steps": [ { "stepType": "kafka", "parameter": { "server": "47.xxx.xxx.xxx:9092", "kafkaConfig": { "group.id": "console-consumer-83505" }, "valueType": "ByteArray", "column": [ "__key__", "__value__", "__partition__", "__timestamp__", "__offset__", "'123'", "event_id", "tag.desc" ], "topic": "testkafka", "keyType": "ByteArray", "waitTime": "10", "beginOffset": "0", "endOffset": "3" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": { "partition": "", "truncate": true, "compress": false, "datasource": "odps_source",// The name of the MaxCompute data source. "column": [ "key", "value", "partition1", "timestamp1", "offset", "t123", "event_id", "tag" ], "emptyAsNull": false, "table": "testkafka" }, "name": "Writer", "category": "writer" } ], "version": "2.0", "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] }, "setting": { "errorLimit": { "record": "" }, "speed": { "throttle": false, "concurrent": 1 } } }To view the values of the group.id parameter and the names of consumer groups, run the kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --list command on the master node of the EMR Kafka cluster.
Sample command:
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --listReturn value:
_emr-client-metrics-handler-group console-consumer-69493 console-consumer-83505 console-consumer-21030 console-consumer-45322 console-consumer-14773
This example uses console-consumer-83505 to demonstrate how to obtain the values of the beginOffset and endOffset parameters by running the kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505 command.
Sample command:
kafka-consumer-groups.sh --bootstrap-server emr-header-1:9092 --describe --group console-consumer-83505Return value:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID testkafka 6 0 0 0 - - - test 6 3 3 0 - - - testkafka 0 0 0 0 - - - testkafka 1 1 1 0 - - - testkafka 5 0 0 0 - - -
Configure a resource group for scheduling.
In the right-side navigation pane of the node configuration tab, click the Properties tab.
In the Resource Group section of the Properties tab, set the Resource Group parameter to the exclusive resource group for Data Integration that you created.
NoteIf you want to write Kafka data to MaxCompute at a regular interval, such as on an hourly basis, you can use the beginDateTime and endDateTime parameters to set the interval for data reading to 1 hour. Then, the node is scheduled to run once per hour. For more information, see Kafka Reader.
Click
 icon to run the code.
icon to run the code.You can operation Log view the results.
What to do next
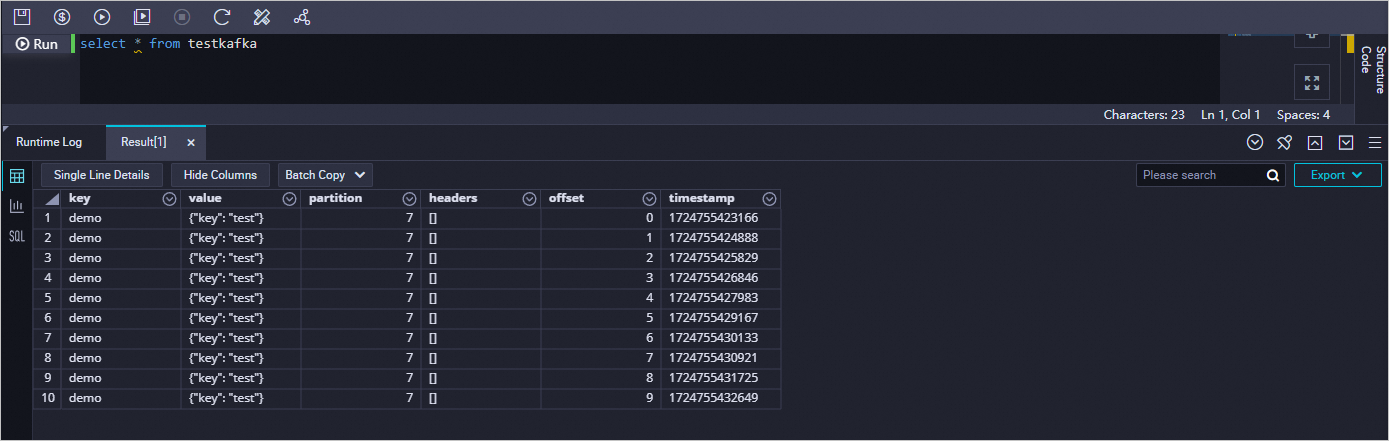
You can create a data development node and run SQL statements to check whether the data has been synchronized from ApsaraMQ for Kafka to the current table. In this example, the select * from testkafka statement is used.
Go to the DataStudio page.
Log on to the DataWorks console.
In the left-side navigation pane, click Workspace to go to the Workspaces page.
In the top navigation bar, select the desired region. On the Workspaces page, find the created workspace and choose in the Actions column to go to the DataStudio page.
In the left-side navigation pane of the DataStudio page, click the
 icon to go to the Ad Hoc Query pane. In the Ad Hoc Query pane, click the
icon to go to the Ad Hoc Query pane. In the Ad Hoc Query pane, click the  icon and choose .
icon and choose . In the Create Node dialog box, configure the Path and Name parameters.
Click Confirm.
On the configuration tab of the ODPS SQL node, enter
select * from testkafka, and click the icon in the top toolbar. After the ODPS SQL node is run, view the operational logs generated for the ODPS SQL node.
icon in the top toolbar. After the ODPS SQL node is run, view the operational logs generated for the ODPS SQL node.