알리바바는 Aliexpress, Tmall 등 중국의 e-commerce 플랫폼에서 시작하여 현재는 많은 아시아권 나라에서 다양한 비즈니스를 수행하고 있습니다. 아시아는 세계에서 가장 높은 인구 분포를 지니고 있는데요. 오늘날 세계 인구 70억명 중 4/7에 이르는 40억명이 중동을 포함한 아시아에서 살고 있다고 합니다. 이는 아시아에서 우세한 비즈니스를 하고 있는 알리바바가 그만큼 많은 데이터를 보유하고 있다는 점을 시사합니다.
알리바바 클라우드에서 제공하는 모든 BigData 관련 서비스는 모두 AliPay, AliExpress, Tmall, Taobao 등 알리바바 비즈니스의 주축을 이루는 모든 계열사의 데이터 분석에서 실제로 활용되고 있는 서비스입니다. 가령, 2019년 11월 11일 중국의 최대 쇼핑페스티벌인 광군제에서는 하루에 1.7EB 의 데이터를 알리바바 클라우드의 BigData Platform에서 처리를 했고, 실시간 데이터 처리엔진인 RealTime Compute(Flink)는 피크타임 시 초당 40억개의 데이터(7 TB)를 consume하여 처리한 바 있습니다.
자, 그럼 본격적으로 알리바바 클라우드의 BigData Service에 대해서 알아보도록 하겠습니다.
알리바바 클라우드 공식 문서 사이트에 가보시면, Big Data와 Databases 카테고리에 다양한 서비스가 있는 것을 확인하실 수 있습니다.

때로는 서비스가 너무 많아서 어떤 서비스를 선택해야할지 막막하시리라 생각합니다. 중첩된 기능을 제공하는 서로 다른 서비스가 있는가 하면, 비슷한 시나리오에 사용할 수 있는 수많은 서비스들이 산재해있습니다.
알리바바가 제공하는 빅데이터 처리 관련 서비스를 처리과정에 따라 나누어 보면 아래와 같습니다.
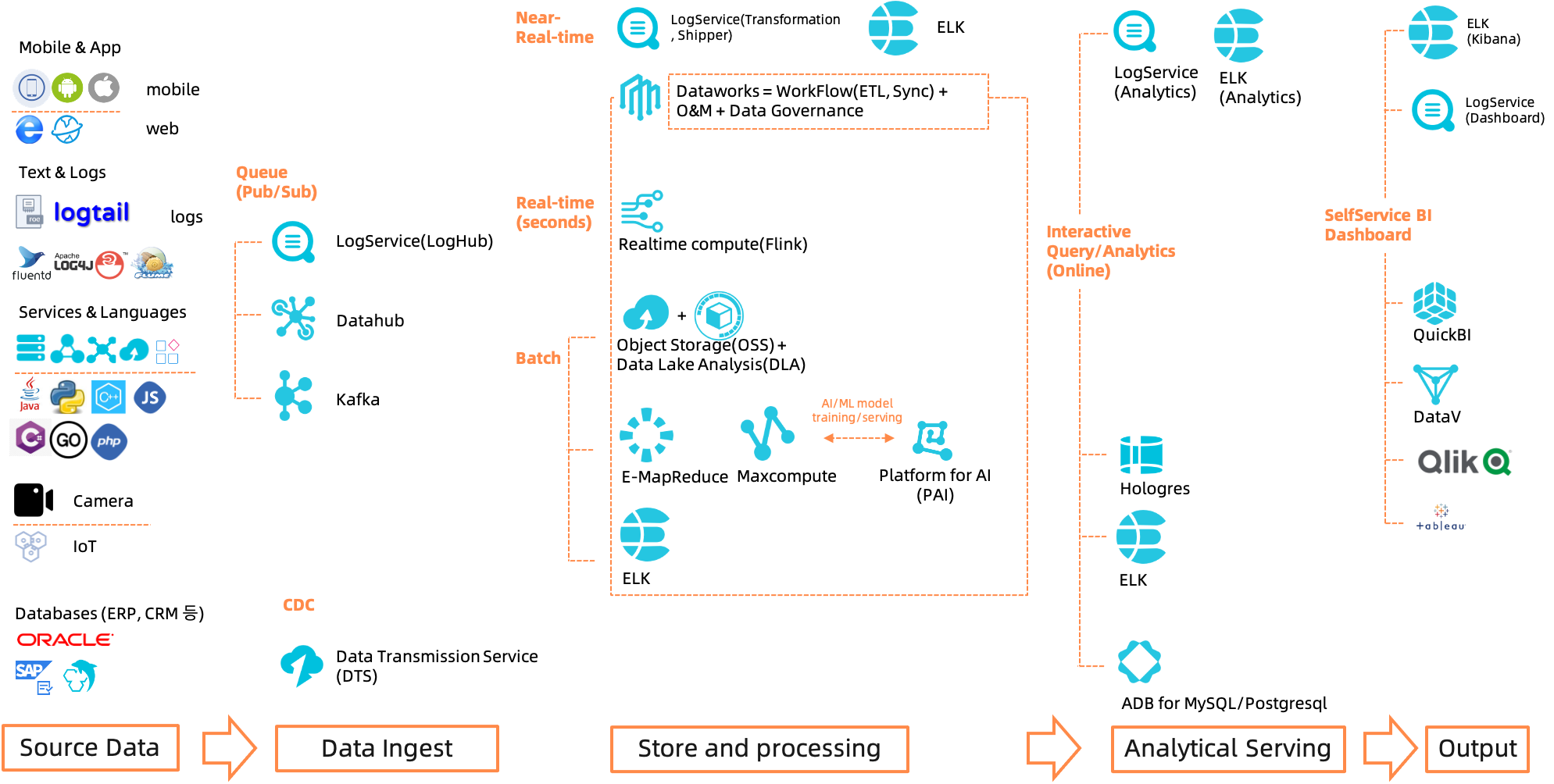
알리바바에서는 대용량의 데이터를 안정적으로 가지고 오기 위하여 아래 3가지 queue를 제공합니다. 모두 관리형 서비스로 제공되므로 사용자는 인프라 유지보수에 관여할 필요가 없습니다. 3개 모두 실시간으로 대용량의 데이터를 가져올 수 있으니 현재 연결하고자 하는 source와 target, 필요로 하는 througput(가령 시간당 1TB 처리 등)과 기능 등을 지원하는지 여부에 따라 서비스를 결정하시면 되겠습니다.
소스 데이터가 ERP/CRM 등에 연결된 데이터베이스라고 한다면 DTS를 통해 DB-to-DB로 실시간 동기화를 수행하거나 일 배치 등을 수행할 수 있습니다.
데이터를 저장하고 처리하는 과정은 일정 시간의 텀을 두고 배치 형태로 처리할지, 수십초 단위의 near-realtime으로 처리할지, 수초 단위의 realtime으로 데이터를 처리할지에 따라 나뉘며 제공되는 서비스는 다음과 같습니다.
DataWorks는 모든 유형의 데이터 분석에 있어 필요한 일련의 작업들, 가령 데이터 수집(Data Integration), 데이터 개발, 스케쥴링, Workflow 정의, Data Governance(Data security, quality check) 등을 수행하는 서비스입니다. 어떤 처리 플랫폼을 선택하던지 간에 Dataworks는 여러분의 데이터를 가지고 작업할 수 있는 통합 작업 공간이 될 것입니다. 예를 들어, OSS의 데이터를 maxcompute로 가져오고 maxcompute에서 일단위 배치작업을 돌린다면, 이 일련의 과정을 DataWorks에서 DAG 형태로 workflow를 정의하고 script를 작성하여 스케쥴링 할 수 있습니다. 또한 Data Quality 기능을 사용하여 데이터 처리과정에서의 문제사항을 사용자에게 즉각 보고하고 Data Security기능을 활용하여 부적절한 data access를 막는 등의 작업을 할 수 있습니다. 여기 소개된 모든 서비스들은 대부분 DataWorks에서 처리 가능합니다.
알리바바 클라우드가 2019년 Enterprise flink platform을 만드는 회사인 Ververica(vvr)를 인수하며 알리바바의 관리형 flink인 realtime compute가 탄생하게 되었습니다. Flink는 10TB/s 수준까지의 대용량 스트리밍 데이터를 실시간으로 처리하기 위해 만들어진 플랫폼입니다. 일반적인 사용 형태는 kafka와 같은 pub/sub 형태의 queue와 함께 사용하여 queue에 데이터를 cache하고 실시간으로 들어오는 순서에 맞게 데이터를 읽어서 처리 후 타겟에 업데이트하는 방식으로 사용됩니다. 사용자 친화적인 SQL/Table API를 통하여 지속적으로 업데이트되는 데이터를 sql문으로 쿼리하여 결과를 target table에 업데이트할 수 있습니다. Spark streaming이 수십초 단위의 latency까지 지원할 수 있는 반면, Realtime compute은 수초 단위의 latency까지 지원하여 전 구간 delay를 획기적으로 줄였습니다.
log service의 data transformation은 200개가 넘는 built-in python 함수를 기반으로 다양한 처리를 수행할 수 있습니다. log service는 이름에서 알 수 있듯이 로그를 처리하기 위하여 만들어진 서비스이기 때문에 소스데이터가 로그라고 한다면 1순위로 고려해보셔야 합니다. 필요없는 field를 제거하거나, 마스킹하거나, text parsing하거나 IP2location 함수등을 이용하여 분석을 위한 필드를 추가하거나 필드 값에 따라 타겟 테이블을 다르게 하는 등의 다양한 작업을 할 수 있습니다. 자세한 사항은 log service의 best practice 항목을 참조해 주시기 바랍니다.
Alibaba Cloud의 Elastic Search는 오픈소스 Elastic Search 기반으로 실시간 쓰기 성능과 스토리지 저장 비용을 감소시키는 등 커널 최적화작업을 거쳐 제공되는 관리형 서비스 입니다. Elastic Search에서 제공되는 Logstash/Beats를 통해 데이터를 수집하고 Kibana로 시각화하여 분석할 수 있습니다. Elastic Search는 다양한 유형의 데이터를 지원하고 강력한 기본 쿼리 기능을 제공하기 때문에 많은 개발자들분들이 채택하여 사용하고 있는 플랫폼입니다.
Note: LogService와 ElasticSearch가 동일 선상에서 사용 가능한 플랫폼이므로 사용성, 기능, 성능, 확장성, 비용 등을 따져서 비즈니스 요구사항에 따라 더 적합한 서비스를 선택하여 사용하시면 됩니다. 자세한 사항은 'LogService와 Elastic Search의 비교 분석'을 클릭하여 확인해 주시기 바랍니다.
아래의 서비스들은 모두 Datworks IDE를 통해 개발, workflow 정의 및 스케쥴링 등을 수행할 수 있습니다.
OSS(Object Storage Service)는 대용량의 (비)정형 데이터를 저렴하게 저장할 수 있는 스토리지 공간입니다. DLA(Data Lake Analysis)는 OSS의 데이터를 쿼리하고 처리할 수 있는 Serverless Preso engine과 Spark engine을 제공합니다. 사용자는 DataWorks로 ETL scheduling 작업을 수행할 수 있습니다. 가장 간단한 작업 환경, 저렴한 가격, 이기종 플랫폼의 데이터들을 불러와 처리할 수 있는 통합 작업 환경을 원하신다면 OSS+DLA를 권장합니다.
Maxcompute는 알리바바가 자체개발한 Apsara Distributed Filesystem(분산파일처리시스템)을 기반으로 만들어진 알리바바 버전의 Hadoop 시스템입니다. Serverless 환경으로 사용자는 저장비용과 처리비용만 지불하면 되어 비용 효율적으로 시스템을 구축/운영할 수 있습니다. SQL, mapreduce, UDF, Graph, Spark job을 처리할 수 있으며 Offline 대용량 데이터 분석용도이기 때문에 latency는 수십초~분 단위입니다. 따라서 셀프서비스 BI나 대시보드 애플리케이션에서 바로 연결하려면 중간에 Hologres를 두는 것이 좋습니다. Hologres는 뒤에서 설명합니다. Maxcompute는 TB 이상(PB, EB)의 대용량 데이터를 높은 성능으로 처리해야할 경우 선택합니다.
EMR은 Hadoop, Spark, Hive, HBase 등 오픈소스 플랫폼을 빠르게 설치 구성하여 사용할 수 있는 서비스입니다. 관리형 서비스가 아니므로 고객이 직접 클러스터 환경을 커스토마이징하여 관리하고자 하는 요구사항이 있을 경우, 오픈소스와의 100% 호환성을 가져가야 하는 경우 사용합니다.
Elasticsearch에 배치형태로 데이터를 넣어야 할 경우, 알리바바가 제공하는 faster-bulk plug-in을 활용하여 대용량 배치 데이터 쓰기 성능을 높일 수 있습니다.
대시보드, BI, 애플리케이션 등에서 바로 붙여서 사용할 수 있는 온라인 데이터 분석 플랫폼입니다. 실시간으로 스트리밍되는 데이터나 배치작업을 끝맞친 최종 데이터를 여기에 두고 실시간 분석을 수행하거나, 검색하거나, 쿼리할 수 있습니다.
LogService는 SQL syntax를 기반으로 다양한 built-in 함수와 쿼리 기능을 제공합니다. 또한 OSS와 MySQL 등 외부 demension table의 데이터를 가져와 조인 쿼리하거나 비슷한 log entry를 클러스터링 하는 LogReduce 기능, 실시간 업데이트 되는 로그 파일을 관찰할 수 있는 LiveTail 기능 등을 사용할 수 있습니다.
온라인 데이터 분석에 필요한 기능적 요소들은 Elasticsearch 공식문서의 DSL과 SQL등을 참조합니다.
Hologres는 HSAP(Hybrid Serving and Analytical Processing) 컨셉에 따라 개발된 알리바바의 차세대 DW 시스템으로 대시보드, 리포트, 동시접속이 많은 애플리케이션 등 여러 시나리오에 복합적으로 적용할 수 있는 단일 접속 플랫폼을 제공합니다. Postgresql 기반이기 때문에 psql 등 postgresql client와 모두 호환되어 대부분의 애플리케이션과 쉽게 연동 가능합니다. 또한 maxcompute의 데이터를 foreign table로 직접 쿼리 가능하기 때문에 cold data는 maxcompute에, warm data 및 실시간 조회가 필요한 데이터는 hologres에 두어 비용을 줄일 수 있습니다.
ADB for MySQL(+ 아래 Postgresql)은 모두 MPP 아키텍쳐를 기반으로 설계된 알리바바의 OLAP 엔진입니다. 필요시 참고하시면 되겠습니다.
알리바바가 자체 개발하여 제공하는 Real-time OLAP data warehouse는 Hologres, AnalyticDB for Postgresql, AnalyticDB for MySQL 이렇게 3가지입니다. 3가지 모두 사용 시나리오가 비슷하여 어떤 서비스를 선택할지 고민인 분들에게는 Hologres를 추천드립니다. 이유는 성능과 가격, maxcompute과의 호환성 때문인데요. 최근에 진행한 TPC-H 벤치마킹 테스트를 비교해보면 Hologres가 더 적은 비용으로 더 빠른 성능을 낸 것을 확인할 수 있었습니다. 100GB의 데이터로 TCP-H의 22개 쿼리를 실행한 결과는 아래와 같습니다.아래의 결과는 외부에 공개되어 있습니다.
| Hologres | ADB for MySQL | |
|---|---|---|
| 사양 | 64 vCPU, 256GB Memory | 48 vCPU, 384GB Memory |
| 성능(22개 쿼리 총 소요시간) | 총 40.870초 | 총 167초 |
| 가격 | 3.403/hour (100GB 저장 공간 비용 포함 | 3.726/hour (100GB 저장 공간 비용 포함) |
최종 데이터에 대한 소비지점은 아래의 서비스들이 될 수 있습니다.
LogService의 Dashboard는 20개가 넘는 차트를 제공하며 고객 시스템에 대시보드를 임베디드하거나 Grafana, Jaeger, quickBI, DataV 등 다른 시각화 툴과 연동하여 사용 가능합니다.
Elasticsearch를 사용할 경우 Kibana 인터페이스를 통해 데이터를 쿼리하거나 대시보드를 구성할 수 있습니다. 알리바바 클라우드 Elasticsearch를 사용하면 이 Kibana가 이미 설치된 형태로 제공됩니다. Kibana 사용법에 대한 자세한 사항은 Kibana Guide를 참조합니다.
알리바바 클라우드의 셀프서비스 형태의 BI 서비스입니다. Tableau나 Qlik와 같이 현업들이 데이터를 가지고 원하는 뷰에 맞게 시각화할 수 있습니다.
종합상황실, 전시회 등에서 사용되는 대시보드를 쉽게 구축할 수 있는 서비스입니다. QuickBI가 현업들이 자유롭게 데이터를 조작하고 시각화하면서 분석하는데 초점을 맞춘 반면, DataV는 정형화된 대시보드를 구축하고 운영하는데 초점이 맞추어진 서비스입니다.
그럼 대용량의 로그 처리/분석해야 하는 시나리오를 가정하여 위의 서비스들을 가지고 빅데이터 파이프라인을 설계를 해보겠습니다.

데이터 수집, 처리, 온라인 분석, 대시보드까지 모두 Log Service에서 수행하는 방법입니다. Log Service 안의 모든 기능을 활용하여 전체 파이프라인을 구성하는 것입니다. Logtail로 로그를 수집하고 logstore에 raw data를 저장합니다. Data transformation 기능을 통해 데이터를 파싱하여 또다른 logstore에 분배합니다. Log Service의 built-in 함수와 쿼리를 통해 온라인 분석을 수행하고 다양한 차트로 대시보드를 구성합니다. 각기 다른 서비스를 연동할 필요 없이 단일 플랫폼으로 구성하기 때문에 가장 간단하고 편리합니다.

Log Service의 logtail로 데이터를 수집하고, loghub queue를 통해 데이터를 Maxcompute와 Elasticsearch로 보냅니다. DataWorks에서 Maxcompute 배치작업을 오케스트레이션하고 처리완료된 최종 데이터를 Hologres로 보냅니다. Maxcompute의 테이블은 다시 DataWorks의 Data Synchronization 기능을 통해 OSS로 아카이빙되거나 Elasticsearch에서 처리작업을 마친 데이터를 다시 maxcompute로 들여올 수 있습니다. Hologres로 모여진 데이터는 대시보드나 BI 분석툴에서 최종 소비됩니다. 이 아키텍처에서 Elasticsearch는 선택사항으로 빠져도 무방합니다.
Log Service의 loghub부터 maxcompute, hologres, OSS 아카이빙까지 모든 작업은 DataWorks에서 수행됩니다. 즉, 작업환경은 DataWorks로 개발자는 단일 작업환경에서 모든 작업을 통합적으로 관리할 수 있습니다.
지금까지 현재시점(2021.09)기준 Alibaba Cloud에서 제공하는 모든 빅데이터 처리 플랫폼을 살펴보고 대용량 로그분석이라는 시나리오를 가정하여 서비스들을 조합하여 시스템을 설계해 보았습니다. 비즈니스 요구사항, 개발자분들의 선호도에 따라 다양한 조합으로 시스템이 구축될 수 있을 것입니다. 시스템 설계에 대해서 궁금한 사항이 있으시면 Alibaba Cloud Korea로 문의주시기 바랍니다.
Regional Content Hub - April 15, 2024
Haemi Kim - October 20, 2021
JJ Lim - September 23, 2021
Regional Content Hub - August 12, 2024
James Lee - October 11, 2023
Regional Content Hub - May 20, 2024
 Realtime Compute for Apache Flink
Realtime Compute for Apache Flink
Realtime Compute for Apache Flink offers a highly integrated platform for real-time data processing, which optimizes the computing of Apache Flink.
Learn More Big Data Consulting for Data Technology Solution
Big Data Consulting for Data Technology Solution
Alibaba Cloud provides big data consulting services to help enterprises leverage advanced data technology.
Learn More MaxCompute
MaxCompute
Conduct large-scale data warehousing with MaxCompute
Learn More Big Data Consulting Services for Retail Solution
Big Data Consulting Services for Retail Solution
Alibaba Cloud experts provide retailers with a lightweight and customized big data consulting service to help you assess your big data maturity and plan your big data journey.
Learn More

